2주일 동안 집중 공부하기
네이버 cue, 쳇 gpt 활용해서 공부 하기
조완희(폴리텍대학), 오미란.문혜영,신면철,김대호,김종일, 김우경, 강윤석, 예정은.황지영, 윤소영 등등 여러교수님들의 유튜브 와 자료 참조해서 공부 했습니다
꼭 합격하자
7월19일 시험결과 88.75점
최종합격자 발표는 8월7일 이다

사무자동화산업기사 자격증이 필요한이유
사무자동화산업기사란 응시자격을 갖춘 자가 산업인력공단에서 시행하는 사무자동화산업기사 시험에 합격하여 그 자격을 취득한 자를 말합니다. 1
사무자동화산업기사는 사무 업무의 효율성을 높이고 업무내용의 질적 향상을 도모하기 위해 사무자동화와 관련한 전문기술인력을 양성하기 위해 제정된 자격입니다.
사무자동화산업기사 자격증은 다양한 이유로 가치가 있으며, 이를 취득하는 것이 여러 방면에서 유리할 수 있습니다. 아래는 사무자동화산업기사 자격증이 필요한 주요 이유들입니다:
1. 업무 효율성 향상
자동화 기술 습득: 사무자동화산업기사 자격증은 문서 처리, 데이터 관리, 보고서 작성 등의 자동화 기술을 습득하게 해줍니다. 이를 통해 업무를 더 빠르고 정확하게 처리할 수 있습니다.
시간 절약: 반복적인 작업을 자동화함으로써 시간을 절약하고, 더 중요한 업무에 집중할 수 있습니다.
2. 경쟁력 강화
취업 기회 확대: 사무자동화산업기사 자격증은 많은 기업에서 요구하는 기본 자격 중 하나입니다. 이를 통해 다양한 직무에 지원할 수 있는 기회가 확대됩니다.
직무 역량 증대: 자격증을 통해 습득한 기술과 지식은 업무 수행 능력을 향상시키며, 이는 직장에서의 경쟁력을 높이는 데 도움이 됩니다.
3. 직장 내 인정
전문성 인정: 사무자동화산업기사 자격증은 해당 분야에서의 전문성을 인정받는 증명서입니다. 이를 통해 동료나 상사로부터 더 높은 신뢰와 인정을 받을 수 있습니다.
진급 및 보상: 자격증 소지자는 업무 능력을 인정받아 진급이나 보상에서 유리한 위치에 설 수 있습니다.
4. 개인 성장 및 발전
기술적 성장: 사무자동화 기술을 습득함으로써 개인의 기술적 성장과 발전을 도모할 수 있습니다.
지식 업데이트: 지속적으로 변화하는 사무자동화 기술을 공부함으로써 최신 기술과 트렌드를 따라갈 수 있습니다.
5. 다양한 산업 분야에서의 활용
범용성: 사무자동화 기술은 제조, 서비스, 금융 등 다양한 산업 분야에서 활용될 수 있습니다. 따라서 자격증 소지자는 여러 분야에서 능력을 발휘할 수 있습니다.
유연한 직무 수행: 사무자동화 기술을 통해 다양한 직무를 보다 유연하고 효율적으로 수행할 수 있습니다.
6. 자격증 요구 추세
기업 요구: 많은 기업에서 사무자동화 기술을 중요하게 여기고 있으며, 이에 따라 관련 자격증 소지자를 우대하는 경우가 많습니다.
정부 및 공공기관: 일부 정부 및 공공기관에서도 사무자동화 자격증을 요구하거나 우대하는 추세가 있습니다.
결론
사무자동화산업기사 자격증은 업무 효율성을 높이고, 취업 및 진급 기회를 확대하며, 다양한 산업 분야에서 활용될 수 있는 중요한 자격증입니다. 이를 통해 개인의 성장과 직장 내 경쟁력을 강화할 수 있습니다.



































































































































































































































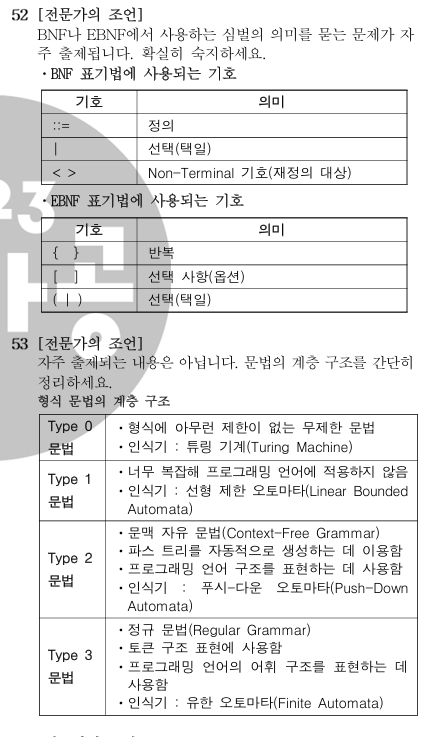








관계형 데이터베이스에서의 정규화란 데이터의 중복을 최소화하고 데이터의 일관성을 유지하며 데이터 조작의 효율성을 높이는 과정을 말합니다. 즉, 테이블 내의 속성들 사이의 종속성을 이용해서 데이터를 분해하는 과정입니다. 이렇게 함으로써 불필요한 데이터의 중복을 제거하고 데이터의 안정성과 일관성을 보장할 수 있습니다.
대표적인 정규화 규칙으로는 다음과 같은 것들이 있습니다.
제1정규형(First Normal Form, 1NF): 릴레이션에 속한 모든 도메인이 원자 값으로만 이루어진 형태입니다.
제2정규형(Second Normal Form, 2NF): 제1정규형에 속하면서 키가 아닌 모든 속성이 기본키에 완전 함수 종속인 형태입니다.
제3정규형(Third Normal Form, 3NF): 제2정규형에 속하면서 키가 아닌 모든 속성이 기본키에 이행적으로 함수 종속이지 않은 형태입니다.
보이스 코드 정규형(Boyce-Codd Normal Form, BCNF): 모든 결정자가 후보키인 정규형입니다.
제4정규형(Fourth Normal Form, 4NF): 다치종속을 제거한 정규형입니다.
제5정규형(Fifth Normal Form, 5NF): 조인 종속성을 제거한 정규형입니다.
다만, 정규화를 지나치게 많이 하면 데이터 조회 시 여러 개의 테이블을 Join해야 하는 문제가 발생하므로 성능 이슈도 고려해야 합니다. 따라서 프로젝트의 성격과 상황에 따라 적절한 수준의 정규화를 적용하는 것이 중요합니다.
RFC(Request for Comments)는 IETF(Internet Engineering Task Force)에서, 인터넷에서 기술을 구현하는 데에 필요한 절차 등을 제공하는 공문서 간행물입니다. RFC는 인터넷 연구와 개발 공동체의 작업 문서로, 인터넷상에서 기술을 구현함에 있어서 요구되는 상세한 절차와 기본 틀을 제공하는 기술 관련 내용을 담고 있습니다. 12
RFC는 전자우편을 통하거나 직접 특정 호스트에 접속하여 FTP로 다운로드할 수 있으며, RFC 색인을 통해 어떤 RFC가 유일한 것인지 아니면 또 다른 RFC에 의해 갱신된 것인지를 확인할 수 있습니다. RFC 색인은 ftp://ftp.ietf.org/rfc/에서 가져올 수 있으며, 파일명은 RFC 디렉터리 아래의 rfc-index.txt입니다. 사용자는 키워드, 제목, 작성자, 발표 기관, 날짜 등의 임의의 필드를 지정해 모든 RFC의 목록을 요청할 수 있습니다.
전자우편 보안 PGP(Pretty Good Privacy)는 전자우편의 암호화와 인증을 위한 도구입니다. PGP는 다음과 같은 기능을 제공합니다.
암호화
PGP는 메시지를 암호화하여 전송할 수 있도록 해줍니다. 암호화된 메시지는 수신자만이 해독할 수 있으며, 중간에서 가로채더라도 내용을 파악할 수 없습니다.
인증
PGP는 메시지의 출처를 인증할 수 있도록 해줍니다. 송신자는 자신의 PGP 키를 이용하여 메시지에 서명을 하고, 수신자는 해당 서명을 검증하여 송신자의 신원을 확인할 수 있습니다.
부인 방지
PGP는 메시지의 송수신 여부를 확인할 수 있도록 해줍니다. 수신자는 받은 메시지에 대한 응답 메시지를 암호화하여 송신자에게 보낼 수 있으며, 송신자는 이를 통해 수신자가 메시지를 받았음을 확인할 수 있습니다.
PGP는 이러한 기능을 통해 전자우편 보안을 강화할 수 있지만, 사용하기 위해서는 PGP 프로그램과 상대방의 PGP 키가 필요하며 설정 과정이 다소 복잡할 수 있습니다.
호프만 부호 검사(Hoffman's Significance Test)는 두 모집단의 평균 차이를 검정하는 비모수 통계량 중 하나입니다. 이 방법은 두 집단의 분산이 동일하다는 가정 하에 이루어지며, 다음과 같은 절차로 진행됩니다.
데이터 수집
먼저, 비교하고자 하는 두 집단의 데이터를 수집합니다.
부호화
각 데이터의 절대값을 취하고, 이를 오름차순으로 정렬합니다. 그리고 첫 번째 데이터와 마지막 데이터의 절대값을 더해줍니다.
통계량 계산
다음과 같이 계산합니다.
S = (첫 번째 데이터 + 마지막 데이터) / 2
T = S - (n+1)/2
여기서 n은 데이터의 개수입니다.
4. 검정 결과 해석
T의 값이 0보다 크면 두 집단의 평균은 다르다고 판단할 수 있습니다. 이때, p-value를 계산하여 유의수준과 비교해 볼 수 있습니다.
주의해야 할 점은 호프만 부호 검사는 두 집단의 분산이 동일하다는 가정이 충족되어야 한다는 것입니다. 만약 그렇지 않을 경우에는 t-test 등 모수 통계학적 방법을 사용하는 것이 좋습니다.
워킹셋(Working Set) 모델은 메모리 관리 기법 중 하나로, 프로세스가 자주 액세스하는 페이지들만을 메모리에 유지하고 그 외의 페이지들은 디스크에 저장하는 방법입니다. 워킹셋 모델은 페이지 교체 알고리즘의 일종으로, 다음과 같은 특징을 가집니다.
페이지 부재율 감소
워킹셋 모델은 프로세스가 자주 액세스하는 페이지들을 메모리에 유지하므로 페이지 부재율이 감소합니다.
처리 속도 향상
워킹셋 모델은 프로세스가 자주 액세스하는 페이지들을 메모리에 유지하므로 처리 속도가 향상됩니다.
메모리 공간 절약
워킹셋 모델은 프로세스가 자주 액세스하지 않는 페이지들을 디스크에 저장하므로 메모리 공간을 절약할 수 있습니다.
하지만 워킹셋 모델에도 단점이 존재합니다. 페이지 교체가 빈번하게 일어나므로 오버헤드가 발생할 수 있고 미리 예상해서 페이지를 가져와야 하므로 추가적인 비용이 들 수 있습니다.
단항 연산자(unary operator)는 하나의 피연산자를 취하는 연산자입니다. 단항 연산자는 주로 변수의 값을 변경하거나 데이터 타입을 변환하는 데 사용됩니다. 대표적인 단항 연산자로는 다음과 같은 것들이 있습니다.
증감 연산자
++, -- 피연산자의 값을 1씩 증가시키거나 감소시킵니다.
부정 연산자
! 피연산자의 논리값을 반전시킵니다.
선언 연산자
sizeof() 피연산자의 크기를 바이트 단위로 반환합니다.
타입 변환 연산자
(type) 피연산자의 데이터 타입을 강제로 변환합니다.
비트 반전 연산자
∼ 피연산자의 비트열을 반전시킵니다.
이외에도 다양한 단항 연산자가 있으며, 각 프로그래밍 언어마다 지원하는 단항 연산자가 다를 수 있습니다. 또한 일부 단항 연산자는 함수 호출처럼 동작하기도 합니다. 예를 들어 sqrt() 함수는 입력받은 값의 제곱근을 반환하는 단항 연산자입니다.
이항 연산자(binary operator)는 두 개의 피연산자를 취하는 연산자입니다. 이항 연산자는 수학 계산에서 자주 사용되며, 다음과 같은 종류가 있습니다.
덧셈(+)
두 수의 합을 구하는 연산자입니다.
뺄셈(-)
두 수의 차를 구하는 연산자입니다.
곱셈(*)**
두 수의 곱을 구하는 연산자입니다.
나눗셈(/)**
두 수의 몫을 구하는 연산자입니다.
나머지(%)**
두 수의 나머지를 구하는 연산자입니다.
보수(^)**
두 수의 비트 XOR 연산을 구하는 연산자입니다.
AND(&)
두 수의 비트 AND 연산을 구하는 연산자입니다.
OR(|)
두 수의 비트 OR 연산을 구하는 연산자입니다.
XOR(^)
두 수의 비트 XOR 연산을 구하는 연산자입니다.
** Shift(<<, >>)**
비트를 왼쪽 또는 오른쪽으로 이동시키는 연산자입니다.
등이 있습니다.
기계어는 컴퓨터가 이해할 수 있는 언어로, 0과 1로 이루어진 이진수로 표현됩니다. 기계어는 인간이 직접 읽고 해석하기 어렵기 때문에 어셈블리어나 고급 프로그래밍 언어를 사용하여 프로그램을 작성하고 컴파일러나 인터프리터를 통해 기계어로 변환합니다.
기계어는 CPU의 종류에 따라 다양한 형식이 있으며, 대부분의 경우 16비트 또는 32비트 단위로 데이터를 처리합니다. 예를 들어, 인텔 x86 계열 CPU에서는 32비트 크기의 명령어 집합인 IA-32가 널리 사용되고 있습니다.
기계어는 하드웨어와 밀접하게 연관되어 있기 때문에 운영체제나 CPU 종류에 따라 서로 다른 형식을 가지고 있습니다. 따라서 특정 시스템에서 실행되는 프로그램을 만들기 위해서는 해당 시스템의 기계어 문법을 이해하고 있어야 합니다.
기계어는 매우 단순하고 직관적이지만, 인간이 직접 읽고 해석하기에는 매우 어렵습니다. 또한, 기계어로 프로그램을 작성하는 것은 매우 번거롭고 시간이 많이 걸리기 때문에 대부분의 경우 어셈블리어나 고급 프로그래밍 언어를 사용하여 프로그램을 작성하고 컴파일러나 인터프리터를 통해 기계어로 변환합니다.
참고정보
퍼스트핏(First-Fit), 베스트핏(Best-Fit), 워스트핏(Worst-Fit)은 메모리 관리에서 사용되는 동적 메모리 할당 전략입니다. 이 전략들은 메모리 블록에 프로세스를 할당하는 방식에 차이가 있으며, 각각의 장단점이 있습니다. 이를 자세히 설명하겠습니다.
퍼스트핏 (First-Fit)
설명
퍼스트핏은 메모리에서 첫 번째로 맞는 빈 블록에 요청된 크기의 메모리를 할당하는 방식입니다.
메모리를 순서대로 탐색하여 첫 번째로 충분히 큰 블록을 찾으면, 그 블록에 메모리를 할당합니다.
장점
빠른 할당: 첫 번째로 맞는 블록을 찾으면 즉시 할당하므로 검색 시간이 짧습니다.
간단한 구현: 알고리즘이 간단하여 구현하기 쉽습니다.
단점
외부 단편화 문제: 메모리 블록들이 부분적으로 사용되어 작은 빈 공간들이 많아질 수 있습니다.
비효율적 메모리 사용: 큰 블록을 잘게 나누지 않기 때문에 메모리 사용의 효율성이 떨어질 수 있습니다.
베스트핏 (Best-Fit)
설명
베스트핏은 메모리에서 가장 적절한 크기의 빈 블록에 요청된 메모리를 할당하는 방식입니다.
메모리를 전부 탐색하여 요청된 크기에 가장 가까운 크기의 빈 블록을 찾습니다.
장점
최소한의 외부 단편화: 가장 작은 빈 블록에 할당하므로 단편화를 줄일 수 있습니다.
효율적 메모리 사용: 남는 공간을 최소화하여 메모리를 더 효율적으로 사용할 수 있습니다.
단점
긴 검색 시간: 모든 빈 블록을 탐색하여 가장 적절한 블록을 찾아야 하므로 시간이 많이 걸립니다.
복잡한 구현: 빈 블록 리스트를 유지하고 정렬해야 하므로 구현이 복잡합니다.
워스트핏 (Worst-Fit)
설명
워스트핏은 메모리에서 가장 큰 빈 블록에 요청된 메모리를 할당하는 방식입니다.
메모리를 전부 탐색하여 가장 큰 빈 블록을 찾고, 그 블록에 메모리를 할당합니다.
장점
큰 블록 유지: 큰 블록을 사용하므로 나중에 큰 메모리 요청이 있을 때 할당할 수 있는 가능성이 큽니다.
적은 외부 단편화: 큰 블록을 나누어 사용하므로 작은 빈 공간들이 덜 발생할 수 있습니다.
단점
긴 검색 시간: 모든 빈 블록을 탐색하여 가장 큰 블록을 찾아야 하므로 시간이 많이 걸립니다.
비효율적 메모리 사용: 큰 블록을 잘게 나누지 않으면 메모리 사용이 비효율적일 수 있습니다.
비교
전략 장점 단점
퍼스트핏 빠른 할당, 간단한 구현 외부 단편화 문제, 비효율적 메모리 사용
베스트핏 최소한의 외부 단편화, 효율적 메모리 사용 긴 검색 시간, 복잡한 구현
워스트핏 큰 블록 유지, 적은 외부 단편화 긴 검색 시간, 비효율적 메모리 사용
결론
각 메모리 할당 전략은 특정 상황에서 더 유리할 수 있습니다. 퍼스트핏은 빠르고 간단하지만 단편화 문제를 야기할 수 있고, 베스트핏은 메모리를 효율적으로 사용하지만 검색 시간이 오래 걸립니다. 워스트핏은 큰 블록을 유지하는 데 유리하지만 검색 시간이 길고 메모리 사용이 비효율적일 수 있습니다. 시스템의 요구사항과 상황에 맞추어 적절한 전략을 선택하는 것이 중요합니다.





























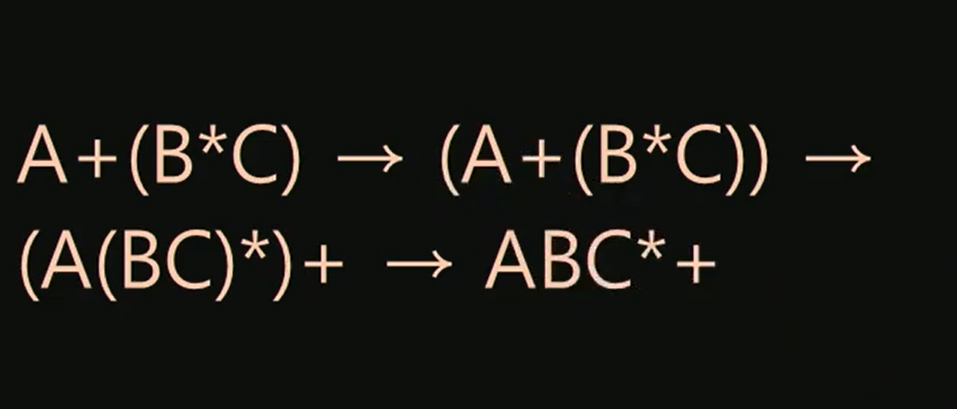






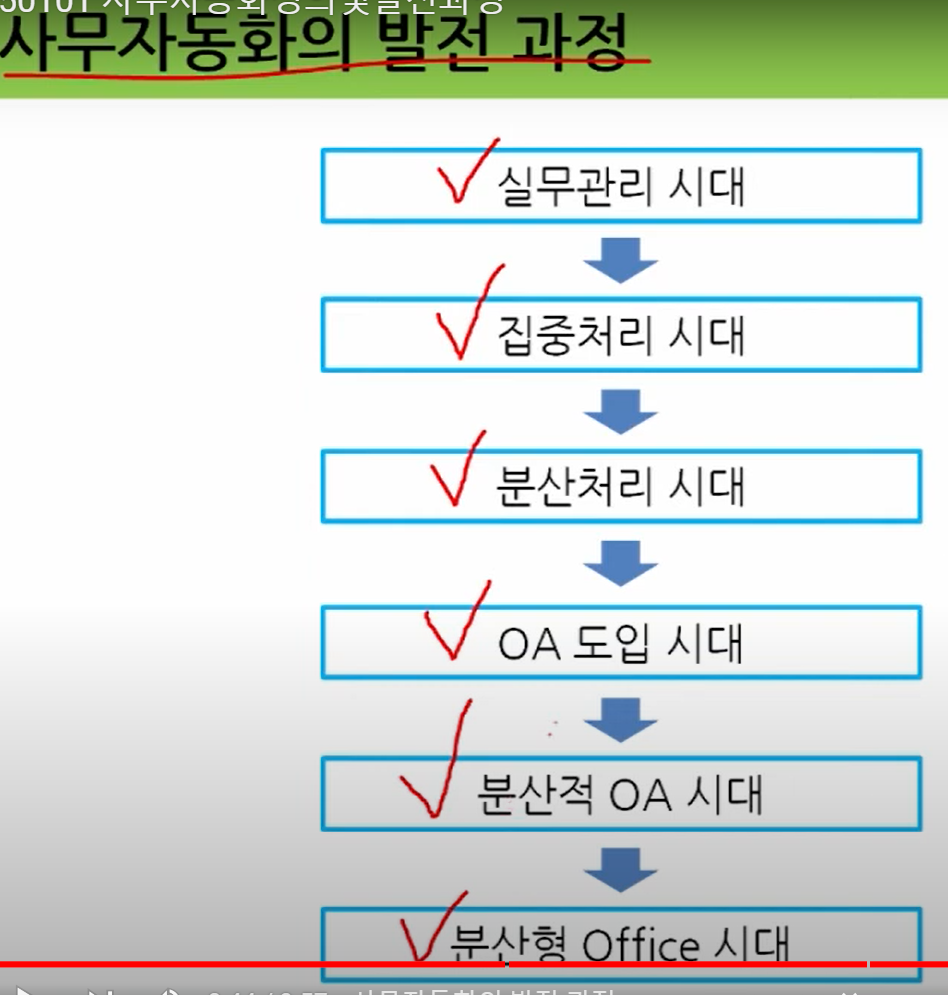
사무자동화 시스템[ 事務自動化~ , office automation system ]
사무실에서 일상적으로 수행하는 정보처리 업무를 자동화시켜 주는 정보 시스템을 말한다. 이 시스템은 문서편집기·표계산기·프레젠테이션 패키지 등 여러 가지 사무자동화 도구로 이루어진다. 사무실의 정보처리 업무는 그 밖에도 전화·전자우편·팩스 등의 도구를 사용한다
[네이버 지식백과] 사무자동화 시스템 [事務自動化~, office automation system] (행정학사전, 2009. 1. 15., 이종수)
경영정보시스템[ management information system음성듣기 , 經營情報─ ]
기업 경영에서 의사결정의 유효성을 높이기 위하여, 경영 내외의 관련 정보를 필요에 따라 즉각적으로, 그리고 대량으로 수집·전달·처리·저장·이용할 수 있도록 편성한 인간과 컴퓨터와의 결합 시스템.
이 경우의 의사결정이란 매우 넓은 뜻의 개념으로서 계층적(階層的)으로는 좁은 뜻의 경영정보 시스템·관리정보 시스템·작업정보 시스템으로 구성되고, 직능별로는 재무·구매(購買)·생산·노무·판매 등의 각 정보 시스템으로 구성된다.
이런 2차적인 각 정보 시스템은 개별적으로 시스템화(化)가 추진되어 온 것으로, 새삼스럽게 경영정보 시스템이라고 주장하는 이유는, 그런 각 기존 시스템의 유기적 결합을 꾀할 필요성이 오늘날 매우 커졌기 때문이다. 컴퓨터의 대용량화와 시스템 엔지니어링(system engineering)의 진보가 이러한 요구에 부응하고 있다.
경영정보 시스템의 설계에 있어서는 발생장소별·용도별·계층별·부문별·보존연한별로 필요한 정보의 종류와 내용을 확정하는 것이 첫째 과제이고, 둘째로는 각 정보의 질과 양을 결정하는 것, 셋째로는 정보의 전달·처리의 신속화를 어떻게 이룩하느냐가 문제가 된다. 이것을 기초로 수집·처리·전달의 네트워크(network)를 조직할 때, 경영정보 시스템이 나타나게 된다.
[네이버 지식백과] 경영정보시스템 [management information system, 經營情報─] (두산백과 두피디아, 두산백과)
VDT(Visual Display Terminal) 증후군은 컴퓨터, 스마트폰, 태블릿 등의 디스플레이 장치를 장시간 사용하면서 발생하는 다양한 신체적 증상을 말합니다. 이 증후군은 디지털 기기의 사용이 증가함에 따라 점점 더 일반화되고 있으며, 주요 증상은 눈의 피로, 시각적 불편, 근골격계 통증 등입니다. VDT 증후군에 대해 자세히 설명하겠습니다.
VDT 증후군의 주요 증상
눈의 피로 (Eye Fatigue)
눈의 건조함 (Dry Eyes): 장시간 화면을 응시하면 눈 깜빡임이 줄어들어 눈이 건조해집니다.
시야 흐림 (Blurred Vision): 오래 화면을 보면 초점 조절이 어려워져 시야가 흐려질 수 있습니다.
눈의 따가움 (Irritation): 화면에서 나오는 블루라이트와 건조한 환경 때문에 눈이 따가워질 수 있습니다.
시각적 불편 (Visual Discomfort)
눈부심 (Glare): 화면의 반사광이나 과도한 밝기로 인해 눈이 부시거나 불편함을 느낍니다.
이중 시력 (Double Vision): 장시간 집중하면 눈의 피로가 쌓여 이중으로 보일 수 있습니다.
색상 왜곡 (Color Distortion): 장시간 사용 후에는 색상을 정확히 인식하기 어려울 수 있습니다.
근골격계 통증 (Musculoskeletal Pain)
목 통증 (Neck Pain): 고정된 자세로 화면을 장시간 보면서 목에 무리가 갈 수 있습니다.
어깨 통증 (Shoulder Pain): 팔의 위치와 화면의 높이가 맞지 않으면 어깨에 통증이 발생할 수 있습니다.
허리 통증 (Back Pain): 오래 앉아 있으면 허리와 등 근육에 무리가 가해져 통증이 생길 수 있습니다.
손목 통증 (Wrist Pain): 키보드와 마우스를 오래 사용하면서 손목에 무리가 갈 수 있습니다.
VDT 증후군의 예방 및 관리 방법
적절한 휴식 (Regular Breaks)
20-20-20 규칙: 20분마다 20초 동안 20피트(약 6미터) 떨어진 곳을 바라보는 규칙을 따릅니다.
짧은 휴식: 매 1시간마다 5~10분간 휴식을 취하고 가벼운 스트레칭을 합니다.
작업 환경 조정 (Adjusting the Work Environment)
화면 위치: 화면의 상단이 눈 높이와 일치하도록 조정합니다.
조명 조절: 눈부심을 최소화하기 위해 적절한 조명을 사용하고 화면 밝기를 조정합니다.
의자와 책상: 인체공학적 의자와 책상을 사용하여 올바른 자세를 유지합니다.
눈 건강 관리 (Eye Health Management)
인공 눈물 사용: 눈이 건조할 때 인공 눈물을 사용합니다.
적절한 깜빡임: 의식적으로 눈을 자주 깜빡여 눈을 촉촉하게 유지합니다.
정기적인 안과 검사: 시력 문제를 조기에 발견하고 치료하기 위해 정기적으로 안과 검사를 받습니다.
운동과 스트레칭 (Exercise and Stretching)
목과 어깨 스트레칭: 간단한 목과 어깨 스트레칭을 통해 근육의 긴장을 완화합니다.
손목 스트레칭: 손목과 손가락을 자주 스트레칭하여 손목 터널 증후군을 예방합니다.
허리 운동: 허리와 등 근육을 강화하는 운동을 정기적으로 합니다.
블루라이트 차단 (Blue Light Blocking)
블루라이트 차단 안경: 블루라이트 차단 렌즈를 사용하여 눈의 피로를 줄입니다.
화면 필터: 블루라이트 차단 필터를 화면에 부착하거나 소프트웨어를 사용하여 블루라이트를 줄입니다.
결론
VDT 증후군은 디지털 기기를 장시간 사용하는 현대인들에게 매우 흔한 문제입니다. 이를 예방하고 관리하기 위해서는 올바른 작업 환경을 조성하고, 규칙적인 휴식과 스트레칭을 실천하며, 눈 건강을 유지하는 것이 중요합니다. 이러한 예방 조치를 통해 VDT 증후군으로 인한 불편함을 최소화하고 건강한 작업 습관을 유지할 수 있습니다.
산업안전기준에서 적정 공기는 작업장에서 근로자의 건강과 안전을 보호하기 위해 중요한 요소입니다. 적정 공기 기준은 작업장 내의 공기 질, 온도, 습도, 환기 등을 포함하며, 이 기준을 충족하기 위해 다양한 조치를 취해야 합니다. 아래는 산업안전기준에서 적정 공기에 대한 주요 사항을 설명합니다.
1. 공기 질 (Air Quality)
유해 물질 농도 제한
작업장 내 공기 중에 존재할 수 있는 유해 물질의 농도를 일정 수준 이하로 유지해야 합니다. 주요 유해 물질 및 그 기준 농도는 다음과 같습니다:
미세먼지 (Dust): PM10, PM2.5 등의 농도를 규제합니다.
화학 물질 (Chemical Substances): 벤젠, 포름알데히드, 암모니아, 등 각종 화학 물질의 허용 농도를 규제합니다.
가스 (Gases): 이산화탄소(CO2), 일산화탄소(CO), 오존(O3), 질소산화물(NOx) 등의 농도를 규제합니다.
2. 온도와 습도 (Temperature and Humidity)
작업장의 온도와 습도는 근로자의 쾌적함과 생산성을 유지하는 데 중요한 역할을 합니다. 적절한 온도와 습도 기준은 다음과 같습니다:
온도 (Temperature):
일반 작업 환경: 18°C ~ 25°C
고온 작업 환경: 냉각 장치 및 충분한 수분 공급을 통해 온도를 낮추는 조치 필요
저온 작업 환경: 난방 장치 및 보온복 제공을 통해 온도를 높이는 조치 필요
습도 (Humidity):
권장 습도 범위: 40% ~ 60%
너무 낮은 습도는 호흡기 및 피부 건조를 유발할 수 있으며, 너무 높은 습도는 불쾌감을 증가시키고 곰팡이 발생을 촉진할 수 있습니다.
3. 환기 (Ventilation)
작업장의 환기는 유해 물질을 제거하고 신선한 공기를 공급하기 위해 필수적입니다. 환기 기준은 다음과 같습니다:
일반 환기: 시간당 최소 6회 이상 공기를 교환하여 신선한 공기를 공급.
국소 배기 (Local Exhaust Ventilation): 유해 물질 발생 장소에 국소 배기 장치를 설치하여 유해 물질을 즉시 제거.
자연 환기: 창문 및 환기구를 통해 자연 공기를 유입하여 실내 공기를 순환.
4. 실내 공기 품질 관리 (Indoor Air Quality Management)
정기 점검 및 유지 보수
공기 질 측정: 정기적으로 공기 질을 측정하여 기준치 초과 여부를 확인.
환기 시스템 유지 보수: 환기 장치의 정기적인 점검과 청소를 통해 효과적인 환기 유지.
필터 교체: 공기 청정기 및 환기 시스템의 필터를 정기적으로 교체하여 공기 청정 효과를 극대화.
청결 유지
청소: 작업장의 청결을 유지하여 먼지 및 오염 물질 축적을 방지.
유해 물질 관리: 유해 화학 물질의 안전한 보관 및 사용 지침을 준수.
5. 법적 기준과 규제 (Legal Standards and Regulations)
한국의 산업안전보건법(KOSHA)에서는 작업장의 적정 공기 기준을 명확히 규정하고 있습니다. 주요 법적 기준은 다음과 같습니다:
공기 중 유해 물질 농도 제한: 각종 유해 물질에 대한 최대 허용 농도를 규제.
환기 기준: 작업장의 환기 시스템 설치 및 운영에 대한 규정.
온도와 습도 조절: 작업 환경에 맞는 적절한 온도와 습도를 유지하도록 규정.
6. 사례: 적정 공기 유지 방안
사례 1: 제조업체의 공기 질 개선
공기 질 측정: 작업장 내 주요 지점에서 정기적으로 공기 질을 측정.
환기 시스템 업그레이드: 기존 환기 시스템을 업그레이드하여 환기 효율을 높임.
공기 청정기 설치: 작업 공간마다 공기 청정기를 설치하여 미세먼지와 유해 물질 제거.
사례 2: 사무실의 쾌적한 환경 유지
자연 환기 활용: 일정 시간마다 창문을 열어 자연 환기를 실시.
적정 온도 및 습도 유지: 온도 조절 장치와 가습기를 사용하여 쾌적한 온도와 습도 유지.
실내 식물 배치: 공기 정화 효과가 있는 실내 식물을 배치하여 공기 질 개선.
결론
산업안전기준에서 적정 공기를 유지하는 것은 근로자의 건강과 안전을 보호하고 작업 환경의 쾌적함을 유지하는 데 필수적입니다. 이를 위해 유해 물질 농도 관리, 적절한 온도와 습도 유지, 효과적인 환기 시스템 운영, 정기적인 공기 질 점검 및 유지 보수 등이 필요합니다. 이러한 조치를 통해 근로자들이 안전하고 건강하게 작업할 수 있는 환경을 제공할 수 있습니다.
산업안전기준에서 소음 기준은 근로자들의 청력을 보호하고 작업 환경의 쾌적함을 유지하기 위해 중요한 요소입니다. 소음은 장시간 노출되면 청력 손상 및 기타 건강 문제를 유발할 수 있기 때문에, 산업 현장에서 이를 관리하는 것은 필수적입니다. 아래는 산업안전기준에서 소음 기준에 대해 설명합니다.
소음 기준의 설정
국제 및 국가별 산업안전기준은 일반적으로 작업장에서 소음 노출을 평가하고 이를 관리하기 위한 권장 기준을 설정하고 있습니다. 주요 기준은 다음과 같습니다:
일일 소음 노출 한계 (Daily Noise Exposure Limit)
85 dB(A): 8시간 작업 기준. 이 수준을 초과하면 청력 보호구(ear protection)를 제공해야 합니다.
90 dB(A): 일부 국가에서는 이 수준을 기준으로 하고 있으며, 이 경우에도 보호구 착용이 필수적입니다.
최대 소음 허용 수준 (Maximum Noise Level)
115 dB(A): 순간 최대 소음 수준으로, 이 수준을 초과해서는 안 됩니다.
청력 보호 구역 설정
85 dB(A) 이상: 이 수준을 초과하는 작업장은 청력 보호 구역으로 지정되어야 하며, 근로자에게 적절한 청력 보호구를 제공해야 합니다.
한국 산업안전보건법의 소음 기준
한국의 산업안전보건법(KOSHA)에서도 소음 기준을 명확히 규정하고 있습니다. 주요 기준은 다음과 같습니다:
소음 작업 기준
8시간 평균 소음 노출 기준: 85 dB(A).
청력 보호구 제공: 근로자의 소음 노출 수준이 85 dB(A)를 초과할 경우, 사업주는 적절한 청력 보호구를 제공하고 착용을 의무화해야 합니다.
소음 관리 프로그램
소음 측정: 정기적으로 작업장의 소음 수준을 측정하여 관리.
청력 보호구 착용 교육: 근로자에게 청력 보호구의 올바른 사용 방법에 대해 교육.
소음 저감 대책: 작업 환경의 소음을 줄이기 위한 방음 벽 설치, 기계의 소음 감소 기술 적용 등.
청력 보존 프로그램
청력 검사: 정기적인 청력 검사를 통해 근로자의 청력을 모니터링하고, 이상이 발견되면 적절한 조치를 취해야 합니다.
소음 노출 기록: 근로자의 소음 노출 기록을 유지하여 소음 노출의 역사적 데이터를 관리.
예시: 소음 관리 방안
소음 저감 기술 적용
방음벽 설치: 소음이 많은 기계 주변에 방음벽을 설치하여 소음을 차단.
흡음재 사용: 작업장 내 벽이나 천장에 흡음재를 설치하여 소음을 흡수.
소음 저감 기계 도입: 소음이 적은 기계 및 장비를 도입.
청력 보호구 제공 및 착용
이어플러그(ear plugs): 간편하게 착용 가능한 청력 보호구.
이어머프(ear muffs): 귀를 완전히 덮어 소음을 차단하는 보호구.
맞춤형 보호구: 근로자의 귀에 맞춤 제작된 청력 보호구 제공.
정기적인 소음 측정 및 모니터링
소음 측정 장비 사용: 작업장의 소음 수준을 주기적으로 측정하여 기록.
소음 지도 작성: 작업장의 소음 분포를 시각적으로 나타내는 소음 지도를 작성하여 관리.
근로자 교육 및 훈련
소음의 위험성 교육: 소음이 건강에 미치는 영향을 교육.
청력 보호구 사용법 교육: 보호구의 올바른 착용 및 관리 방법 교육.
결론
산업 현장에서의 소음 관리와 기준 준수는 근로자의 건강과 안전을 보호하기 위해 매우 중요합니다. 적절한 소음 기준을 설정하고 이를 관리하기 위한 프로그램을 운영함으로써 작업 환경의 쾌적함을 유지하고 청력 손상을 예방할 수 있습니다.
사무실의 조도는 업무의 효율성과 작업자의 편안함에 큰 영향을 미칩니다. 각 작업 공간의 용도에 따라 적절한 조도를 유지하는 것이 중요합니다. 조도는 조명에서 빛의 밝기를 측정하는 단위로, 단위는 럭스(lux)입니다. 아래는 사무실 용도별로 권장되는 조도 기준입니다.
사무실 용도별 권장 조도
일반 사무실 (General Office Work)
권장 조도: 300~500 lux
일반적인 데스크 작업, 문서 작업, 전화 통화 등 대부분의 사무실 작업에 적합한 조도입니다. 이 수준은 눈의 피로를 줄이고 작업 효율성을 높이는 데 도움이 됩니다.
컴퓨터 작업실 (Computer Workstations)
권장 조도: 300~500 lux
모니터의 반사를 최소화하고 눈의 피로를 줄이기 위해 조도를 적절히 조정하는 것이 중요합니다.
회의실 (Meeting Rooms)
권장 조도: 500 lux
프레젠테이션, 토론, 회의 등 다양한 활동을 지원하기 위해 충분한 조도가 필요합니다. 그러나 프로젝터를 사용할 때는 조도를 조절할 수 있어야 합니다.
디자인 및 창의 작업 공간 (Design and Creative Workspaces)
권장 조도: 750~1000 lux
세밀한 작업, 디자인, 그래픽 작업 등을 위해 높은 조도가 필요합니다. 색상과 디테일을 명확히 보기 위해 밝은 조도가 필수적입니다.
접수처 및 로비 (Reception and Lobby Areas)
권장 조도: 200~300 lux
편안하고 환영하는 분위기를 조성하기 위한 적절한 조도 수준입니다. 너무 밝거나 어두우면 첫인상이 나빠질 수 있습니다.
복사실 및 파일실 (Copy Rooms and File Storage Areas)
권장 조도: 300 lux
문서와 파일을 쉽게 찾고 읽을 수 있도록 충분한 조도가 필요합니다.
계단 및 복도 (Stairways and Corridors)
권장 조도: 100~200 lux
안전한 이동을 위해 적절한 조도가 필요합니다. 너무 어두우면 사고 위험이 높아집니다.
휴게실 및 라운지 (Break Rooms and Lounges)
권장 조도: 200~300 lux
편안한 분위기를 제공하여 직원들이 휴식을 취할 수 있도록 하는 데 적합한 조도입니다.
조도 측정 및 관리
조도를 적절히 유지하기 위해서는 조명 설계와 정기적인 조도 측정이 중요합니다. 조도를 측정하기 위해 럭스미터(lux meter)를 사용할 수 있습니다. 또한, 자연광과 인공 조명의 균형을 맞추는 것도 중요합니다.
조도 관리 팁
자연광 활용: 창문을 통해 들어오는 자연광을 최대한 활용하되, 직사광선은 블라인드나 커튼으로 조절하여 눈부심을 방지합니다.
조명 배치: 작업 공간에 적절하게 조명을 배치하여 그림자와 눈부심을 최소화합니다.
조명 조절 장치: 디머(dimmer) 스위치나 자동 조도 조절 장치를 사용하여 조도를 필요에 따라 조절할 수 있도록 합니다.
정기적인 점검: 조명 기구와 전구를 정기적으로 점검하고 필요 시 교체하여 항상 적절한 조도를 유지합니다.
적절한 조도를 유지하면 사무실 환경이 개선되어 업무 효율성이 높아지고, 직원들의 만족도와 건강도 향상될 수 있습니다.
사무표준은 조직의 업무를 일관되게 수행하고 효율성을 높이기 위해 설정된 규칙, 절차, 지침 등을 말합니다. 이러한 표준은 업무의 질을 유지하고, 업무 과정에서 발생할 수 있는 오류를 최소화하며, 직원들 간의 협업을 촉진하는 데 중요한 역할을 합니다. 사무표준의 종류는 다양하며, 아래에서 주요한 몇 가지 종류를 설명합니다.
1. 문서 표준 (Document Standards)
정의
문서 표준은 문서 작성, 형식, 보관, 배포 등에 관한 규칙과 지침을 포함합니다.
종류
문서 형식 표준: 문서의 레이아웃, 글꼴, 크기, 머리글/바닥글 등의 통일된 형식을 규정.
문서 작성 지침: 보고서, 메모, 이메일 등의 작성 방식과 내용 구조를 규정.
문서 보관 표준: 문서의 분류, 저장, 보관 기간, 폐기 절차 등을 규정.
문서 배포 표준: 문서의 배포 방법, 배포 권한, 배포 시기 등을 규정.
2. 업무 절차 표준 (Procedure Standards)
정의
업무 절차 표준은 특정 업무를 수행하는 단계별 절차와 방법을 명확히 규정한 것입니다.
종류
일상 업무 절차: 일상적인 사무 업무를 수행하는 데 필요한 절차와 방법.
프로젝트 관리 절차: 프로젝트를 계획, 실행, 관리, 완료하는 과정에 대한 지침.
문제 해결 절차: 문제가 발생했을 때의 대응 방법과 해결 절차.
의사결정 절차: 의사결정을 내리는 과정과 기준을 규정.
3. 품질 표준 (Quality Standards)
정의
품질 표준은 업무 수행의 질을 유지하고 향상시키기 위한 기준을 포함합니다.
종류
서비스 품질 표준: 고객 서비스, 응대 태도, 응답 시간 등의 기준.
제품 품질 표준: 생산 제품의 품질 기준, 검사 방법, 품질 보증 절차.
내부 감사 표준: 내부 프로세스와 절차의 준수 여부를 점검하는 기준과 방법.
4. 성과 평가 표준 (Performance Standards)
정의
성과 평가 표준은 직원들의 업무 성과를 평가하는 기준과 지침을 포함합니다.
종류
직무 성과 표준: 각 직무에 대해 기대되는 성과와 목표.
평가 방법 표준: 성과 평가의 방법, 주기, 평가 항목 등의 규정.
피드백 표준: 평가 결과에 대한 피드백 제공 방식과 시기.
5. 보안 표준 (Security Standards)
정의
보안 표준은 조직의 정보와 자산을 보호하기 위한 규칙과 지침을 포함합니다.
종류
정보 보안 표준: 데이터 보호, 접근 권한 관리, 암호화 방법 등의 규정.
물리적 보안 표준: 건물 출입 통제, 보안 장치 사용, 비상 절차 등의 규정.
사이버 보안 표준: 네트워크 보안, 바이러스 방지, 침입 탐지 등의 규정.
6. 윤리 표준 (Ethical Standards)
정의
윤리 표준은 직원들이 업무를 수행할 때 준수해야 할 윤리적 기준과 행동 지침을 포함합니다.
종류
윤리 강령: 조직의 가치, 비전, 윤리적 행동 기준을 명시.
이해 상충 방지 표준: 이해 상충 상황에서의 행동 지침과 보고 절차.
비윤리적 행위 신고 절차: 비윤리적 행위를 신고하는 방법과 보호 조치.
7. 환경 표준 (Environmental Standards)
정의
환경 표준은 조직의 활동이 환경에 미치는 영향을 최소화하기 위한 규칙과 지침을 포함합니다.
종류
자원 사용 표준: 에너지 절약, 자원 재활용, 폐기물 관리 등의 규정.
환경 영향 평가 표준: 프로젝트나 활동의 환경 영향을 평가하는 기준과 방법.
친환경 제품 표준: 친환경 제품 개발, 구매, 사용에 관한 지침.
요약
사무표준은 조직의 효율성과 일관성을 높이기 위한 다양한 규칙과 지침을 포함합니다. 문서 표준, 업무 절차 표준, 품질 표준, 성과 평가 표준, 보안 표준, 윤리 표준, 환경 표준 등 다양한 종류가 있으며, 각 표준은 조직의 특정 목표와 요구사항에 맞춰 설정됩니다. 이러한 표준을 통해 조직은 업무의 질을 유지하고, 효율성을 높이며, 직원 간 협업을 촉진할 수 있습니다.
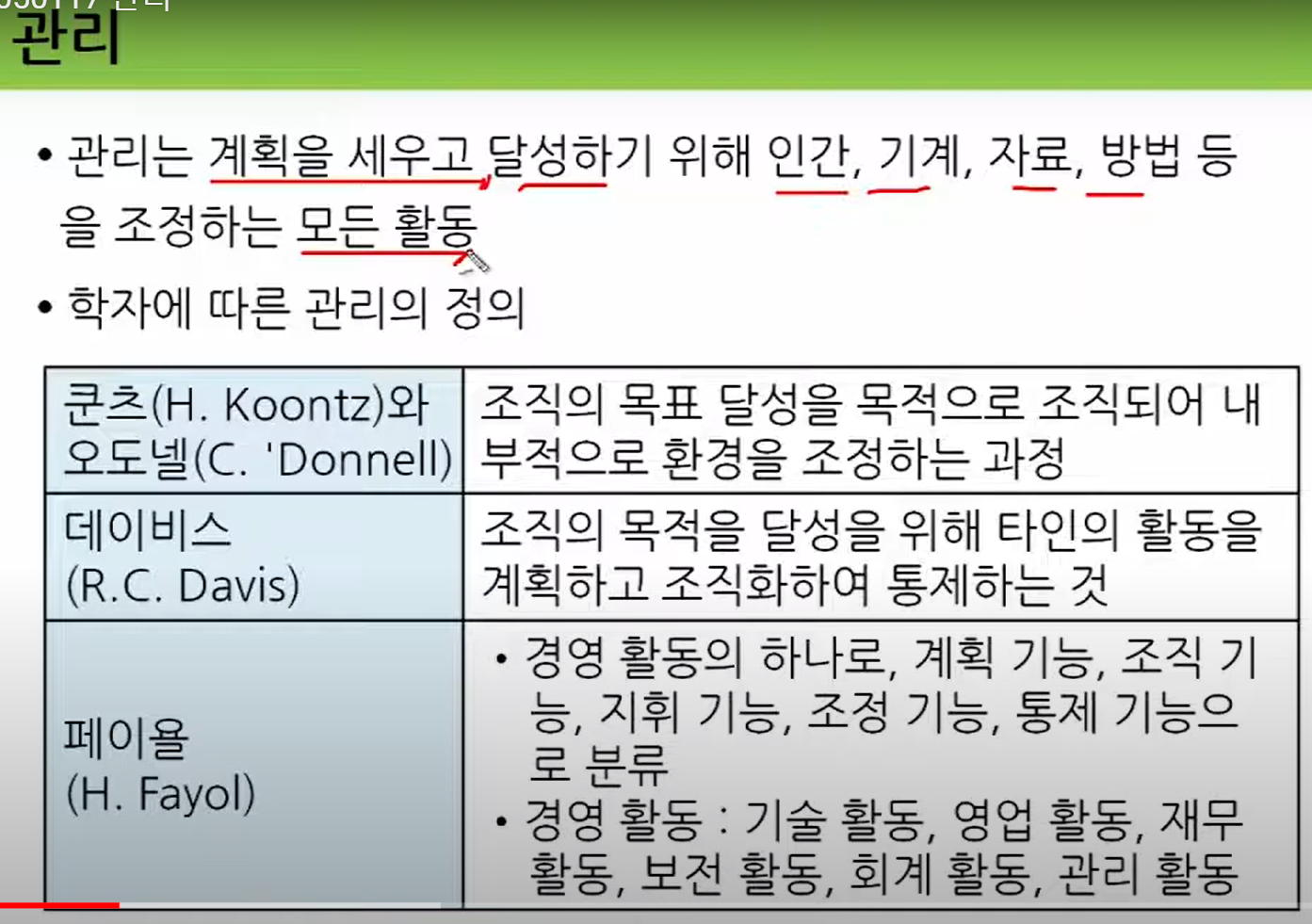
쿠츠와 오도넬(Koontz & O'Donnell)은 경영학 분야에서 잘 알려진 학자들로, 이들은 경영 통제의 중요성과 체계를 제시하였습니다. 그들의 사무통제 개념은 조직이 목표를 달성하기 위해 필요한 모든 활동을 효과적으로 조정하고 감독하는 것을 강조합니다.
사무통제의 정의와 중요성
사무통제는 조직의 목표를 달성하기 위해 사무업무를 관리하고 조정하는 활동을 의미합니다. 이는 계획된 결과와 실제 결과를 비교하여 차이를 식별하고, 필요한 경우 수정 조치를 취하는 과정을 포함합니다. 사무통제는 조직의 효율성과 효과성을 높이는 데 중요한 역할을 합니다.
쿠츠와 오도넬의 사무통제 개념
쿠츠와 오도넬은 사무통제를 다음과 같은 과정으로 설명합니다:
기준 설정 (Setting Standards):
통제의 첫 번째 단계는 조직의 목표와 일치하는 기준을 설정하는 것입니다. 이러한 기준은 성과를 평가하는 데 사용됩니다.
기준은 구체적이고 측정 가능해야 하며, 시간, 비용, 품질 등의 측면에서 설정될 수 있습니다.
성과 측정 (Measuring Performance):
실제 성과를 측정하여 설정된 기준과 비교합니다.
성과 측정은 정기적으로 수행되어야 하며, 신뢰할 수 있는 데이터와 정보를 기반으로 해야 합니다.
실제 성과와 기준 비교 (Comparing Performance with Standards):
실제 성과와 설정된 기준을 비교하여 차이를 분석합니다.
차이가 발생할 경우, 그 원인을 파악하고 해결 방안을 모색합니다.
수정 조치 (Taking Corrective Action):
기준과 실제 성과 간의 차이를 줄이기 위해 수정 조치를 취합니다.
수정 조치는 문제의 원인에 따라 다양한 형태로 이루어질 수 있으며, 프로세스 개선, 추가 교육, 자원 재배치 등이 포함될 수 있습니다.
사무통제의 유형
예방적 통제 (Preventive Control):
문제가 발생하기 전에 이를 방지하기 위한 통제입니다.
교육 및 훈련, 정책 및 절차 수립, 표준 운영 절차(SOP) 등이 포함됩니다.
탐지적 통제 (Detective Control):
문제가 발생했을 때 이를 식별하기 위한 통제입니다.
감사, 검토, 보고서 분석 등이 포함됩니다.
수정적 통제 (Corrective Control):
문제를 해결하고 다시 발생하지 않도록 조치하는 통제입니다.
수정 계획, 재교육, 프로세스 변경 등이 포함됩니다.
쿠츠와 오도넬의 사무통제의 중요성
목표 달성 보장: 조직의 목표와 성과를 일치시키는 데 도움을 줍니다.
효율성 증대: 자원을 효과적으로 사용하고 낭비를 줄일 수 있습니다.
문제 해결: 문제를 신속히 식별하고 해결하여 조직의 원활한 운영을 유지합니다.
책임성 강화: 직원들이 자신들의 업무에 대한 책임감을 갖고 일하게 합니다.
사례: 사무통제의 적용
사례 1: 금융 회사의 사무통제
기준 설정: 월간 재무 보고서 제출 기한 설정.
성과 측정: 실제 보고서 제출 일자와 기한 비교.
비교: 제출 지연이 발생한 경우 분석.
수정 조치: 지연 원인 파악 후 프로세스 개선 및 직원 재교육.
사례 2: 제조업체의 품질 관리
기준 설정: 제품 불량률 1% 이하 유지.
성과 측정: 생산 라인에서의 실제 불량률 측정.
비교: 불량률이 1%를 초과한 경우 분석.
수정 조치: 불량 원인 분석 후 생산 공정 개선 및 품질 검사 강화.
결론
쿠츠와 오도넬의 사무통제 개념은 조직이 목표를 효과적으로 달성하고 효율성을 극대화하는 데 필수적인 요소입니다. 이를 통해 조직은 지속적인 개선을 도모하고, 직원들의 책임감을 강화하며, 운영의 일관성을 유지할 수 있습니다. 사무통제는 모든 조직에서 성공적인 경영을 위해 반드시 필요하며, 이를 효과적으로 구현하는 것이 조직의 장기적인 성공에 중요한 역할을 합니다.
사무처리방식의 결정은 조직의 효율성과 생산성을 높이기 위해 중요한 역할을 합니다. 사무처리방식은 업무 프로세스를 어떻게 설계하고 실행할 것인지에 대한 결정이며, 조직의 운영에 직접적인 영향을 미칩니다. 이를 결정하기 위해 다양한 요소를 고려해야 합니다.
사무처리방식 결정의 중요 요소
업무의 성격:
업무가 정형화된 반복 작업인지, 창의적이고 비정형화된 작업인지에 따라 적절한 처리방식을 선택해야 합니다.
조직의 목표와 전략:
조직의 목표와 전략에 부합하는 방식이어야 합니다. 예를 들어, 고객 만족을 최우선으로 하는 조직은 고객 서비스 관련 사무처리에 중점을 둬야 합니다.
기술적 인프라:
조직의 기술적 역량과 현재 사용 중인 시스템을 고려하여 처리방식을 결정해야 합니다. 최신 기술을 도입하여 효율성을 높일 수 있는지 평가해야 합니다.
자원의 활용:
인력, 시간, 예산 등의 자원을 효과적으로 활용할 수 있는 방식을 선택해야 합니다.
법적 및 규제 요구사항:
관련 법규와 규제를 준수하는 사무처리방식을 도입해야 합니다.
사무처리방식의 유형
수작업 처리방식 (Manual Processing):
사람이 직접 모든 업무를 수행하는 방식입니다.
장점: 유연성이 높고, 예외 상황에 대한 대처가 용이합니다.
단점: 시간이 많이 걸리고, 오류 발생 가능성이 높습니다.
자동화 처리방식 (Automated Processing):
컴퓨터 시스템과 소프트웨어를 사용하여 업무를 자동으로 처리하는 방식입니다.
장점: 효율성과 정확성이 높으며, 대량의 업무를 신속하게 처리할 수 있습니다.
단점: 초기 도입 비용이 높고, 시스템 유지 보수가 필요합니다.
하이브리드 처리방식 (Hybrid Processing):
수작업과 자동화를 혼합하여 사용하는 방식입니다.
장점: 수작업의 유연성과 자동화의 효율성을 결합할 수 있습니다.
단점: 관리가 복잡할 수 있습니다.
사무처리방식 결정의 절차
업무 분석:
각 업무의 특성과 요구사항을 파악합니다. 어떤 업무가 자동화에 적합한지, 어떤 업무가 수작업으로 남아야 하는지를 분석합니다.
목표 설정:
사무처리방식의 도입 목표를 명확히 설정합니다. 예를 들어, 처리 시간 단축, 비용 절감, 오류 감소 등이 목표가 될 수 있습니다.
옵션 평가:
다양한 사무처리방식을 평가하고, 각각의 장단점을 분석합니다. 기술적 인프라, 비용, 구현 시간, 직원 교육 필요성 등을 고려합니다.
파일럿 테스트:
선택한 사무처리방식을 소규모로 시범 운영하여 실제 적용 가능성을 평가합니다.
구현 및 피드백:
최종적으로 결정한 사무처리방식을 전사적으로 도입하고, 지속적인 피드백을 통해 개선해 나갑니다.
사례
사례 1: 은행의 사무처리 자동화
목표: 고객 서비스 개선과 운영 비용 절감.
처리방식: 기존의 수작업 대출 심사 과정을 자동화 시스템으로 전환.
결과: 대출 심사 시간이 크게 단축되고, 오류 발생이 감소.
사례 2: 제조업체의 하이브리드 처리방식 도입
목표: 생산 라인의 효율성 증대와 품질 관리 강화.
처리방식: 생산 과정의 데이터 수집 및 분석은 자동화하고, 품질 검사는 인간이 수행.
결과: 생산 효율성이 증가하고, 제품 불량률이 감소.
결론
사무처리방식의 결정은 조직의 전반적인 효율성과 생산성에 큰 영향을 미칩니다. 각 조직은 업무의 특성과 목표에 맞는 최적의 사무처리방식을 선택해야 하며, 이를 통해 경쟁력을 강화할 수 있습니다. 이러한 결정은 신중한 분석과 평가, 파일럿 테스트, 지속적인 개선 과정을 통해 이루어져야 합니다.
안소프의 의사결정 이론은 경영학 및 전략 관리 분야에서 중요한 개념입니다. Igor Ansoff는 의사결정을 다양한 차원에서 이해하고 분석하기 위해 체계적인 접근법을 제안했습니다. 이를 통해 기업은 효과적인 전략을 수립하고 실행할 수 있습니다. 안소프의 이론에서 가장 잘 알려진 도구는 안소프 매트릭스(Ansoff Matrix)입니다.
안소프 매트릭스(Ansoff Matrix)
안소프 매트릭스는 기업이 성장 전략을 수립할 때 사용하는 도구로, 제품과 시장의 두 가지 축을 사용하여 네 가지 주요 전략을 제시합니다.
시장 침투(Market Penetration):
기존 제품을 기존 시장에서 더 많이 판매하는 전략입니다.
목표는 시장 점유율을 높이고, 고객 충성도를 강화하며, 경쟁사를 제치고 시장 내에서의 지배력을 강화하는 것입니다.
주로 가격 인하, 마케팅 강화, 판매 촉진 등의 방법을 사용합니다.
시장 개발(Market Development):
기존 제품을 새로운 시장에 진출시키는 전략입니다.
새로운 시장은 지리적 지역, 새로운 세그먼트, 새로운 유통 채널 등을 포함할 수 있습니다.
이 전략은 기업이 새로운 고객 기반을 확보하고 매출을 증가시키기 위해 사용됩니다.
제품 개발(Product Development):
기존 시장에 새로운 제품을 개발하여 제공하는 전략입니다.
목표는 기존 고객의 요구를 더 잘 충족시키고, 고객 충성도를 높이며, 추가적인 매출을 창출하는 것입니다.
연구 개발(R&D), 제품 개선, 제품 다양화 등을 통해 이 전략을 실행합니다.
다각화(Diversification):
새로운 제품을 새로운 시장에 도입하는 전략입니다.
가장 위험하지만 잠재적으로 높은 수익을 가져올 수 있는 전략입니다.
다각화는 관련 다각화(기존 제품/시장에서의 기술, 자원 등을 활용)와 비관련 다각화(완전히 새로운 제품/시장)로 나눌 수 있습니다.
안소프의 의사결정 차원
안소프는 의사결정을 세 가지 차원에서 분석했습니다:
전략적 의사결정:
기업의 장기적인 방향과 목표를 설정합니다.
새로운 시장 진입, 신제품 개발, 주요 투자 결정 등이 포함됩니다.
경영진이 주로 참여하며, 불확실성과 높은 리스크를 동반합니다.
전술적 의사결정:
전략적 의사결정을 지원하고 이를 실행하기 위한 구체적인 계획과 방법을 수립합니다.
마케팅 캠페인, 가격 전략, 유통 채널 관리 등이 포함됩니다.
중간 관리자가 주로 참여하며, 중간 수준의 리스크와 불확실성을 동반합니다.
운영적 의사결정:
일상적인 업무와 관련된 결정으로, 조직의 효율적인 운영을 목표로 합니다.
생산 일정 관리, 인력 배치, 재고 관리 등이 포함됩니다.
현장 관리자와 직원이 주로 참여하며, 낮은 리스크와 불확실성을 동반합니다.
안소프 의사결정의 중요성
전략 수립: 안소프의 이론은 기업이 명확한 전략을 수립하고 이를 통해 성장 기회를 극대화하도록 돕습니다.
리스크 관리: 다양한 전략을 통해 리스크를 분석하고 관리할 수 있도록 지원합니다.
시장 및 제품 분석: 제품과 시장의 관계를 체계적으로 분석하여 최적의 성장 경로를 찾을 수 있습니다.
경쟁 우위 확보: 효과적인 전략적 의사결정을 통해 경쟁사보다 유리한 위치를 선점할 수 있습니다.
안소프의 의사결정 이론과 매트릭스는 기업이 시장과 제품의 관점에서 성장 기회를 분석하고 이를 통해 전략을 수립하는 데 중요한 도구로 사용됩니다. 이를 통해 기업은 지속 가능한 성장과 성공을 도모할 수 있습니다.
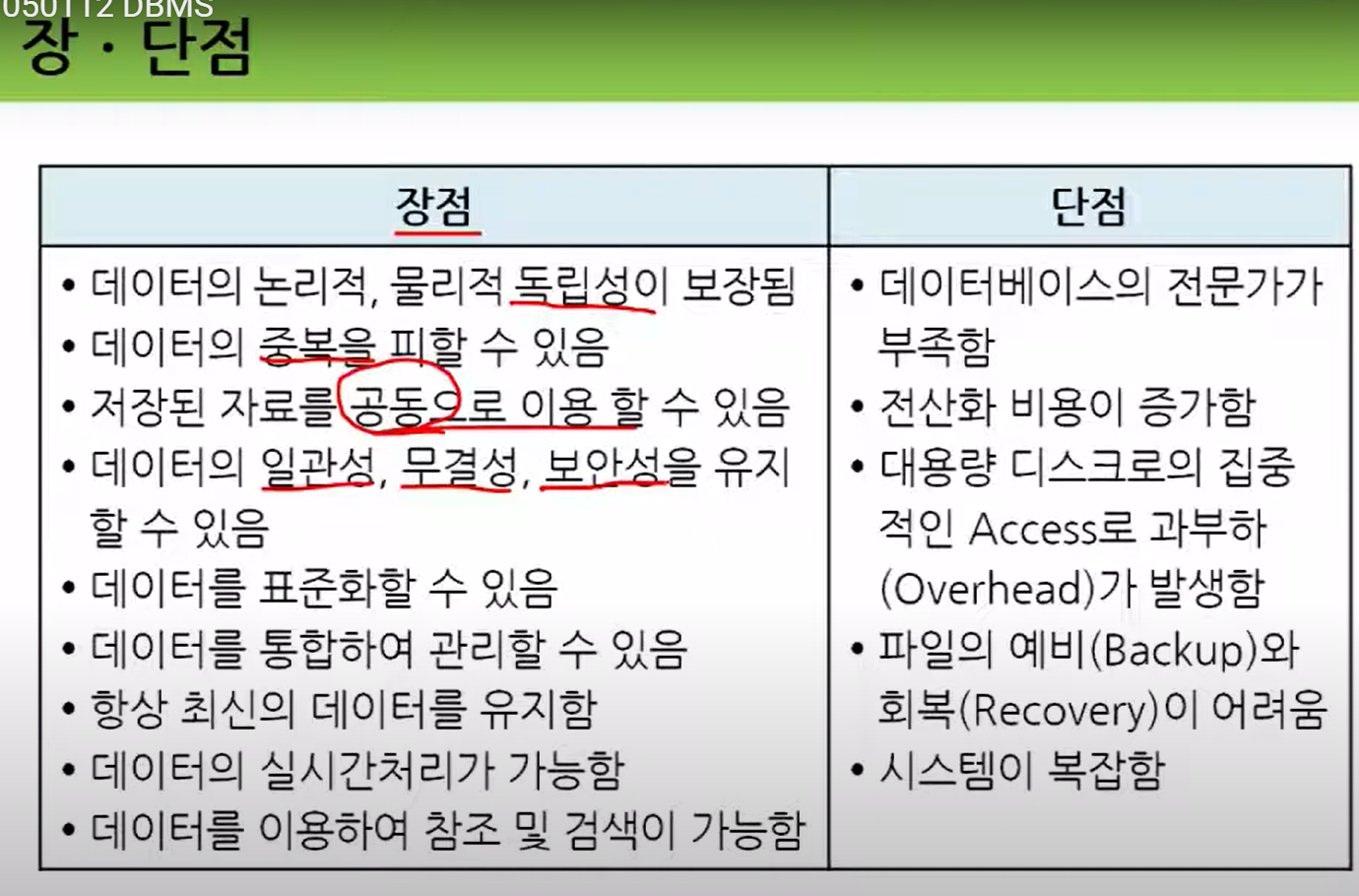
사무관리와 정보관리는 조직의 운영 효율성을 높이고 정보의 정확성을 유지하는 데 중요한 역할을 합니다. 두 개념은 종종 밀접하게 연결되어 있지만, 각자의 고유한 기능과 목표를 가지고 있습니다. 아래에서 각 개념에 대해 자세히 설명하겠습니다.
사무관리
정의
사무관리는 조직 내의 사무 업무를 체계적으로 계획하고 조직화하며 조정하고 통제하는 과정입니다. 주로 문서 처리, 일정 관리, 자원 배분, 의사소통 등 일상적인 행정 업무를 포함합니다.
주요 활동
문서 관리:
문서의 작성, 수집, 분류, 저장 및 폐기.
전자 문서 관리 시스템(EDMS)을 사용해 디지털 문서 관리.
일정 관리:
회의 일정, 업무 일정, 중요한 기한 등을 관리.
캘린더 시스템이나 프로젝트 관리 도구를 사용.
의사소통:
내부 및 외부 커뮤니케이션을 효과적으로 수행.
이메일, 전화, 메모 등 다양한 방법을 통해 의사소통.
자원 관리:
사무실 장비, 비품 및 인력의 효율적인 배치 및 사용.
예산 관리와 비용 절감을 위해 자원 최적화.
업무 흐름 관리:
업무 프로세스를 분석하고 개선하여 효율성 증대.
워크플로우 관리 시스템을 활용.
목표
효율적인 업무 수행 보장.
시간과 비용 절감.
조직 내 커뮤니케이션 및 협업 증진.
정보관리
정의
정보관리는 데이터를 수집, 저장, 처리, 분석 및 배포하여 조직의 의사결정에 필요한 정보를 제공하는 과정입니다. 주로 정보 시스템, 데이터베이스, 네트워크 등을 통해 정보의 흐름을 관리합니다.
주요 활동
데이터 수집 및 저장:
다양한 소스에서 데이터를 수집하고 안전하게 저장.
데이터베이스 관리 시스템(DBMS)을 사용.
데이터 처리 및 분석:
데이터를 정리하고 분석하여 유의미한 정보를 도출.
데이터 분석 도구와 소프트웨어를 활용.
정보 보안:
정보의 기밀성, 무결성 및 가용성을 보장.
암호화, 접근 제어, 백업 및 복구 시스템 사용.
정보 배포:
필요한 정보를 적시에 올바른 사람에게 전달.
보고서 작성, 대시보드 및 정보 시스템 활용.
IT 인프라 관리:
하드웨어, 소프트웨어 및 네트워크의 관리 및 유지보수.
클라우드 서비스 및 가상화 기술 도입.
목표
신뢰할 수 있고 정확한 정보 제공.
조직의 전략적 의사결정 지원.
정보의 안전한 관리 및 보호.
사무관리와 정보관리의 관계
연계성
효율성 증대: 사무관리와 정보관리는 모두 조직의 운영 효율성을 높이는 데 기여합니다. 예를 들어, 문서 관리 시스템은 정보 관리의 일부로, 사무 관리의 문서 처리 효율성을 높입니다.
정보 흐름: 사무관리는 정보가 조직 내에서 원활하게 흐르도록 하며, 정보관리는 이러한 정보를 체계적으로 관리하여 필요한 시점에 제공할 수 있게 합니다.
기술 사용: 현대 사무관리와 정보관리는 모두 IT 기술에 크게 의존합니다. 클라우드 서비스, 데이터베이스, 협업 도구 등이 두 분야 모두에서 사용됩니다.
차이점
초점: 사무관리는 주로 일상적인 행정 업무의 효율성에 초점을 맞추고, 정보관리는 데이터의 수집, 처리 및 분석에 중점을 둡니다.
도구와 시스템: 사무관리는 문서 관리 시스템, 일정 관리 도구 등을 주로 사용하며, 정보관리는 데이터베이스, 분석 도구, 정보 보안 시스템 등을 사용합니다.
요약
사무관리: 조직의 행정 업무를 체계적으로 관리하여 운영 효율성을 높이는 과정.
정보관리: 데이터를 체계적으로 관리하여 조직의 의사결정을 지원하는 과정.
두 개념 모두 조직의 성공적인 운영에 필수적이며, 서로 긴밀하게 연관되어 있습니다. 효율적인 사무관리와 정보관리는 조직의 목표 달성에 중요한 역할을 합니다.
테일러 과학적 관리법 장점
1.
효율성 향상: 테일러의 방법, 특히 시간 및 동작 연구는 작업을 수행하는 가장 효율적인 방법을 찾아 생산성을 높이는 것을 목표로 합니다.
2.
표준화: 각 작업을 수행하는 ‘최선의 방법’을 정립함으로써 전반적으로 일관된 방법과 표준이 마련되어 변동성과 오류가 줄어듭니다.
3.
명확한 역할과 책임: 과학적 관리법은 경영진과 작업자 간의 명확한 역할과 책임 분담을 지지합니다.
4.
과학적 접근: 체계적인 연구와 관찰을 통해 보다 객관적이고 데이터에 기반한 관리 방식을 도입합니다.
5.
더 높은 임금: 테일러는 효율성을 높이면 기업이 근로자에게 더
과학적 사무관리는 조직의 업무를 과학적인 방법으로 분석하고 최적화하여 효율성과 생산성을 높이는 기법입니다. 다음은 과학적 사무관리의 특징입니다.
체계적
과학적 사무관리는 체계적인 방법으로 문제를 파악하고 해결책을 모색합니다. 이를 위해 데이터를 수집하고 분석하며, 실험을 통해 검증합니다.
계량적
객관적인 지표를 활용하여 측정 가능한 결과를 도출합니다. 이를 통해 업무의 성과를 정확하게 평가하고 개선할 수 있습니다.
분석적
원인과 결과를 분석하여 문제를 진단하고 해결 방안을 찾습니다. 이를 통해 업무의 비효율성을 제거하고 생산성을 높일 수 있습니다.
사무관리에는 다양한 기능이 있지만 그중에서도 대표적인 두 가지는 다음과 같습니다.
관리 기능
이는 조직 내에서의 업무 수행 및 자원 관리를 지원하는 기능들을 포함합니다. 예를 들어, 일정 관리, 작업 할당, 예산 관리, 인력 관리 등이 여기에 해당됩니다. 이러한 기능들은 조직의 생산성과 효율성을 높이는 데 큰 역할을 합니다.
정보 기능
이는 데이터 수집, 분석, 보고 등을 위한 기능들을 포함합니다. 예를 들어, 회계 시스템, 고객 관계 관리(CRM), 전사적 자원 관리(ERP) 등이 여기에 해당됩니다. 이러한 기능들은 조직의 의사 결정에 필요한 정보를 제공함으로써 비즈니스 성과 향상에 기여합니다.
조직의 규모와 목적에 따라 추가적인 기능이 필요할 수도 있습니다. 예를 들어, 보안 강화, 자동화, 인공지능(AI) 적용 등이 그러한 경우입니다. 따라서 사무 관리는 유연하면서도 체계적인 접근 방식이 필요합니다.
사무관리는 기업이나 기관에서 이루어지는 일상적인 업무를 효율적으로 처리하고 관리하는 데 필요한 일련의 활동을 말합니다. 아래는 대표적인 세 가지 기능입니다.
문서작성
회사나 조직에서는 수많은 서류와 문서를 작성하고 저장하고 관리해야 합니다. 문서 작성 기능은 워드프로세서나 스프레드시트 등의 소프트웨어를 사용하여 텍스트, 숫자, 이미지 등을 입력하고 편집하는 역할을 담당합니다.
이메일/메신저
이메일과 메신저는 직원 간의 커뮤니케이션을 위한 가장 보편적인 수단 중 하나입니다. 이메일 클라이언트와 메신저 앱을 사용하여 동료들과 빠르게 소통하고 파일을 공유할 수 있으며, 업무 진행 상황을 확인하고 조율할 수 있습니다.
일정관리
일정관리는 프로젝트나 업무 일정을 계획하고 관리하는 기능입니다. 달력이나 스케줄러를 사용하여 일정을 등록하고 수정하고 알림을 설정할 수 있습니다. 이를 통해 업무 우선순위를 정하고 일정 지연을 방지할 수 있습니다.
이외에도 데이터베이스 관리, 재무회계, 인사관리 등 여러 가지 기능이 있을 수 있습니다. 각 조직의 특성과 요구사항에 맞게 적절한 기능을 선택하고 조합하여 효율적인 사무관리를 구현할 수 있습니다.
사무 관리 목표는 조직이나 개인이 업무를 효율적으로 수행하고 성과를 극대화하기 위한 전략 및 계획 수립, 일정 조정, 자원 관리, 의사소통, 문제 해결 등 다양한 활동을 포함합니다. 이러한 목표들은 조직의 목적과 방향성에 따라 다르며 일반적으로는 다음과 같습니다.
효율성
사무 관리는 작업 또는 프로세스를 최대한 빠르고 효과적으로 완료하는데 중점을 둡니다. 이를 위해서는 적절한 도구와 방법론을 선택하고 최적화해야 합니다.
효과성
조직의 목적 달성에 기여하는 결과를 창출하는 것이 주요 목표입니다. 이는 올바른 결정과 행동을 통해 이루어지며, 필요한 자원과 인력을 적절하게 할당함으로써 개선됩니다.
생산성
주어진 시간 내에 더 많은 일을 처리하고 높은 품질의 결과물을 만들어내는 능력을 말합니다. 생산성 향상을 위해서는 불필요한 작업을 줄이고 자동화를 도입하는 등의 노력이 필요합니다.
안정성
시스템과 데이터의 안정성과 보안을 유지하면서 신뢰도를 높이는 것이 중요합니다. 이를 위해서는 백업 및 복구 절차를 마련하고 주기적인 업데이트와 검사를 실시해야 합니다.
유연성
상황 변화에 대처할 수 있도록 유연한 대응력을 갖추는 것이 중요합니다. 이를 위해서는 정책과 규칙을 탄력적으로 적용하고, 인재들의 역량 강화를 위한 교육 프로그램을 운영해야 합니다.
투명성
모든 이해관계자들에게 공정하고 투명한 방식으로 정보를 공개하고 소통하는 것이 중요합니다. 이를 위해서는 기록 보관과 감사 추적을 철저하게 시행하고, 보고 체계를 확립해야 합니다.
이러한 목표들을 균형있게 추구하면 조직의 성장과 발전에 큰 도움이 됩니다. 또한 지속적인 평가와 피드백을 통해 문제점을 발견하고 개선해 나가는 과정이 필수적입니다.
사무관리 순환 구조는 기업 또는 조직 내에서 업무 처리 과정에서 발생하는 문서나 자료 등을 체계적으로 관리하고 보관하는 시스템입니다. 이를 위해 다양한 단계와 절차가 있으며, 대표적인 사무관리 순환 구조는 다음과 같습니다.
계획 수립
먼저 계획을 수립해야 합니다. 이 단계에서는 목표와 방향을 정하고, 필요한 자원과 예산을 파악합니다.
문서 작성 및 수집
문서 작성 및 수집 단계에서는 관련 문서를 작성하고 수집합니다. 이때 문서는 정확하고 일관성이 있어야 하며, 보존 기간을 고려하여 정리되어야 합니다.
보관 및 관리
보관 및 관리 단계에서는 문서를 안전하게 보관하고 관리합니다. 이 단계에서는 보안과 백업 등을 고려하여 적절한 방법으로 보관하고, 주기적으로 점검하여 손상되거나 분실되지 않도록 해야 합니다.
검색 및 활용
검색 및 활용 단계에서는 필요한 문서를 빠르게 찾아서 활용할 수 있도록 합니다. 이 단계에서는 검색 엔진을 이용하여 쉽게 검색할 수 있도록 하고, 필요한 경우에는 수정하거나 보완하여 사용합니다.
폐기
마지막으로 폐기 단계에서는 불필요한 문서를 삭제하거나 폐기합니다. 이 단계에서는 보존 기간을 고려하여 적절한 시기에 폐기하도록 하고, 개인정보 보호 등을 고려하여 신중하게 처리해야 합니다.
이러한 사무관리 순환 구조는 기업이나 조직의 생산성 향상과 효율적인 업무 처리에 중요한 역할을 합니다. 또한, 문서의 보존과 관리를 통해 역사적인 가치를 보존하고 미래 세대에게 전달하는 데에도 기여합니다.
패킷 교환 방식은 데이터 전송 시 데이터를 작은 조각인 패킷 단위로 나누어 전송하고, 목적지에서 다시 재조립하는 방식입니다. 이 방식은 통신망 내의 모든 노드는 패킷을 저장하고 전송할 수 있어야 하며, 다음과 같은 특징이 있습니다.
효율성
패킷 단위로 전송하므로 전송 속도가 빠르고 효율적입니다.
유연성
패킷의 전송 순서와 도착 순서가 다를 수 있기 때문에 유연한 대처가 가능합니다.
신뢰성
오류 검출과 정정 기능을 통해 신뢰성 있는 전송을 보장합니다.
패킷 교환 방식은 크게 메시지 지향형 패킷 교환(MOPEX)과 데이터그램 패킷 교환(DPEX)으로 나눌 수 있습니다.
메시지 지향형 패킷 교환(MOPEX): 메시지를 일정한 크기의 패킷으로 분할하여 전송하고, 수신 측에서 패킷을 재조립하여 메시지를 완성하는 방식입니다.
데이터그램 패킷 교환(DPEX): 패킷마다 개별적으로 경로를 결정하여 전송하는 방식으로, 전송 순서와 상관없이 도착 순서대로 재조립하여 데이터를 완성합니다.
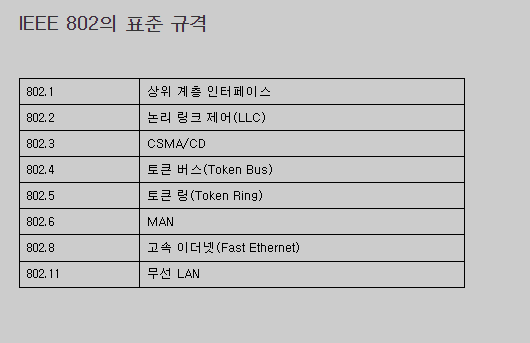
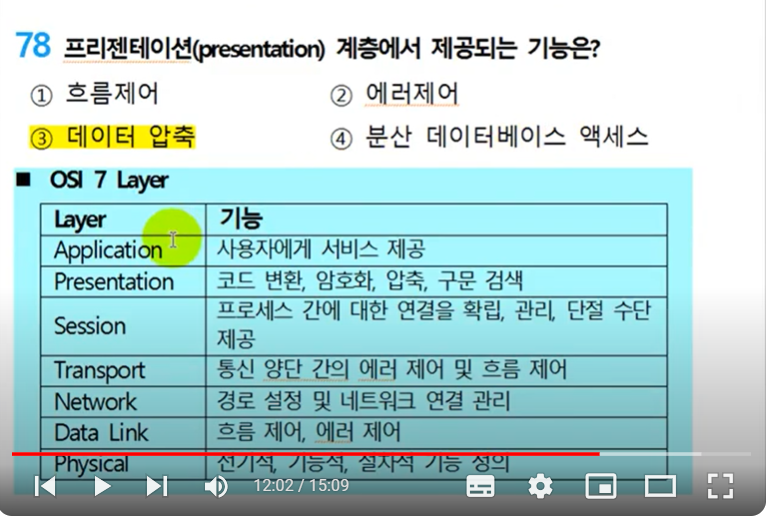
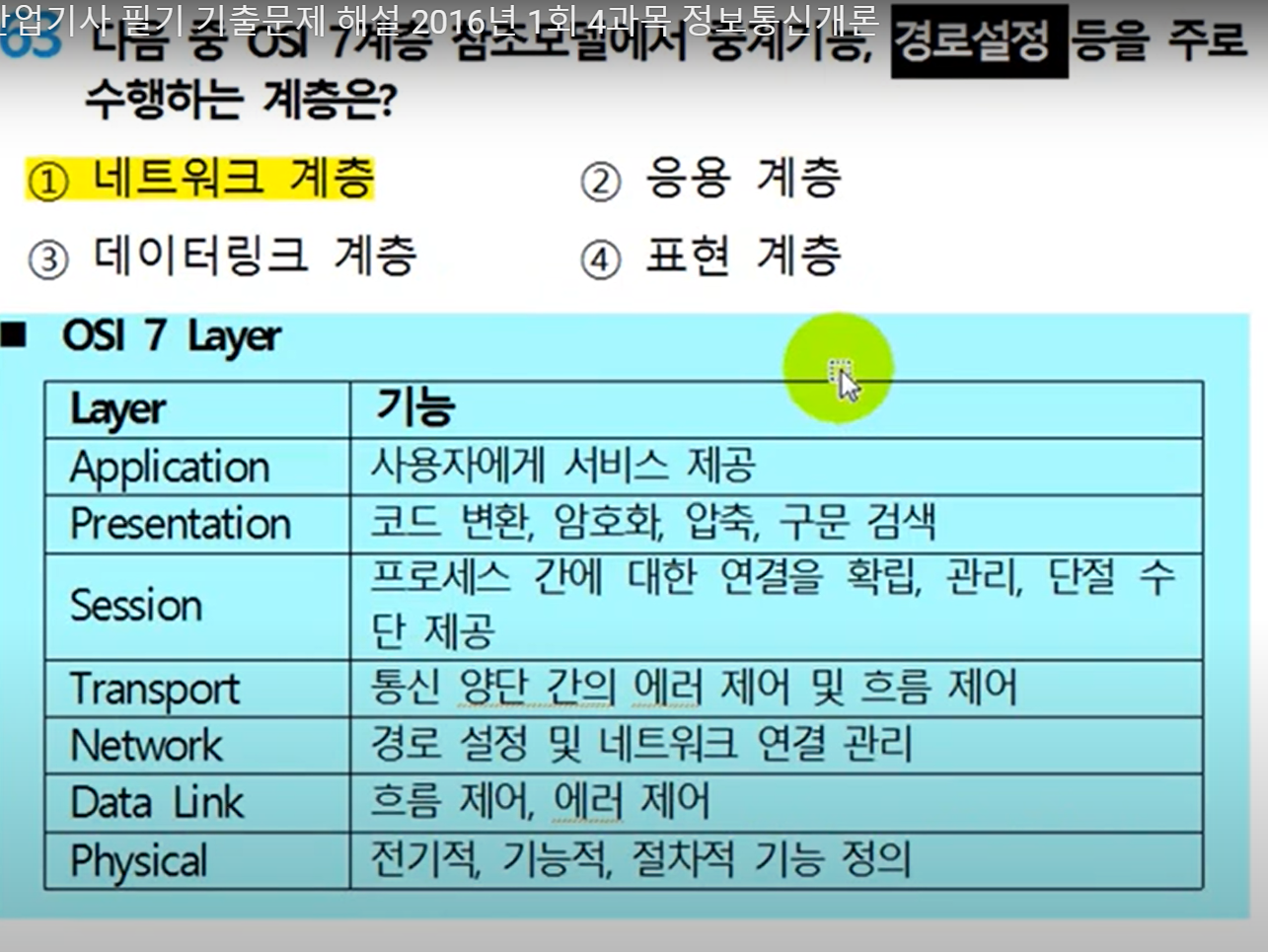
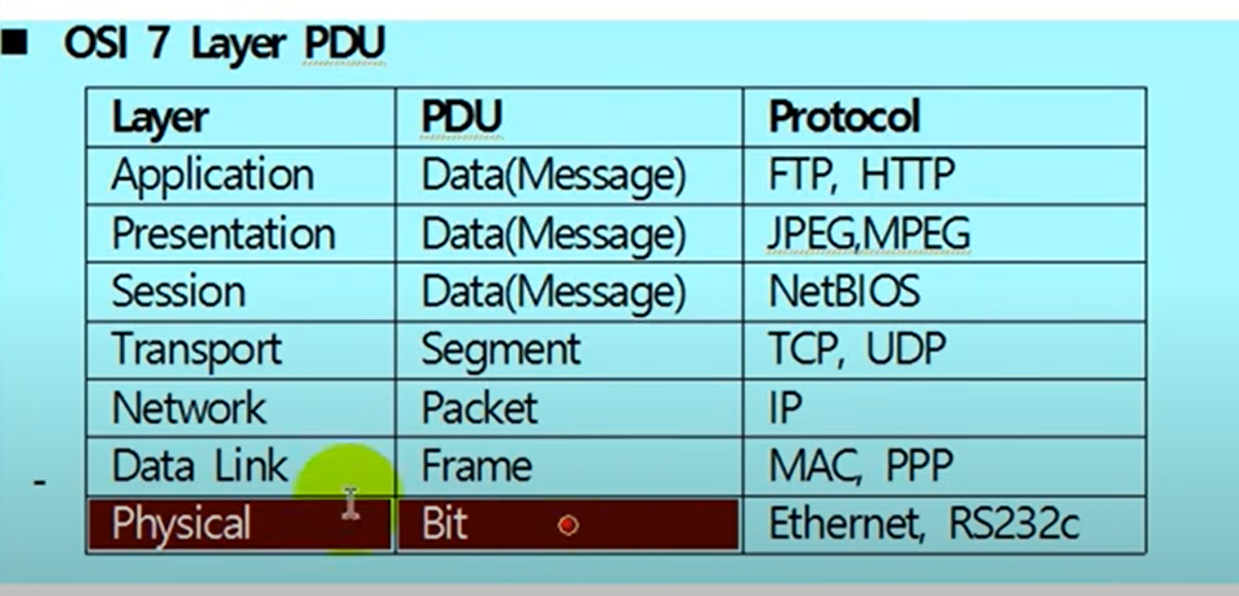
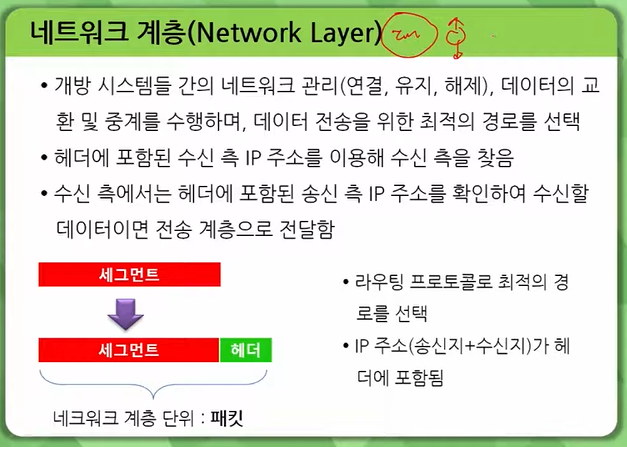
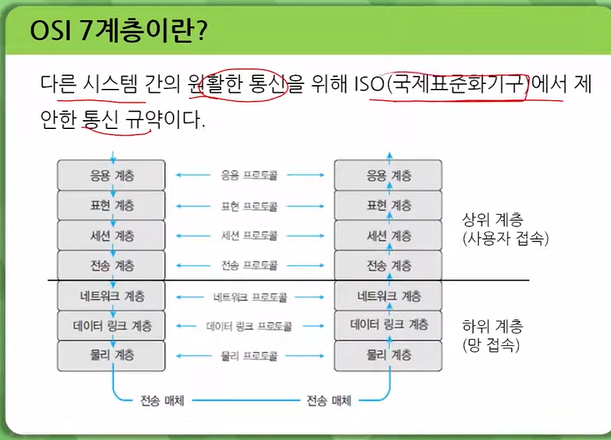
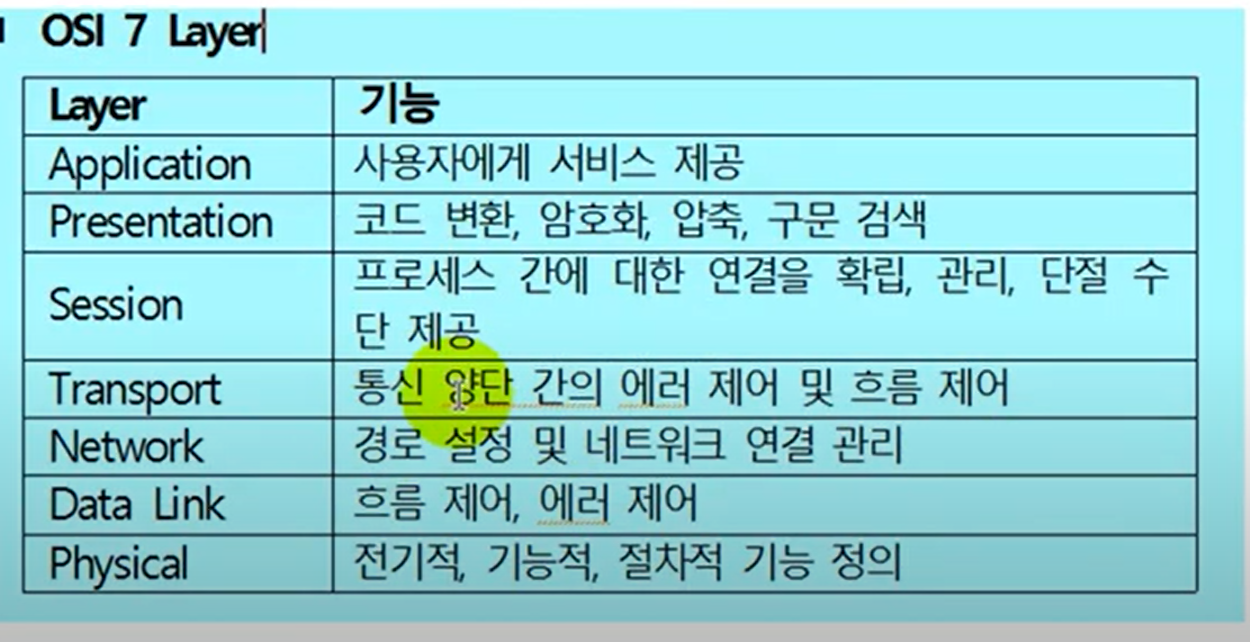
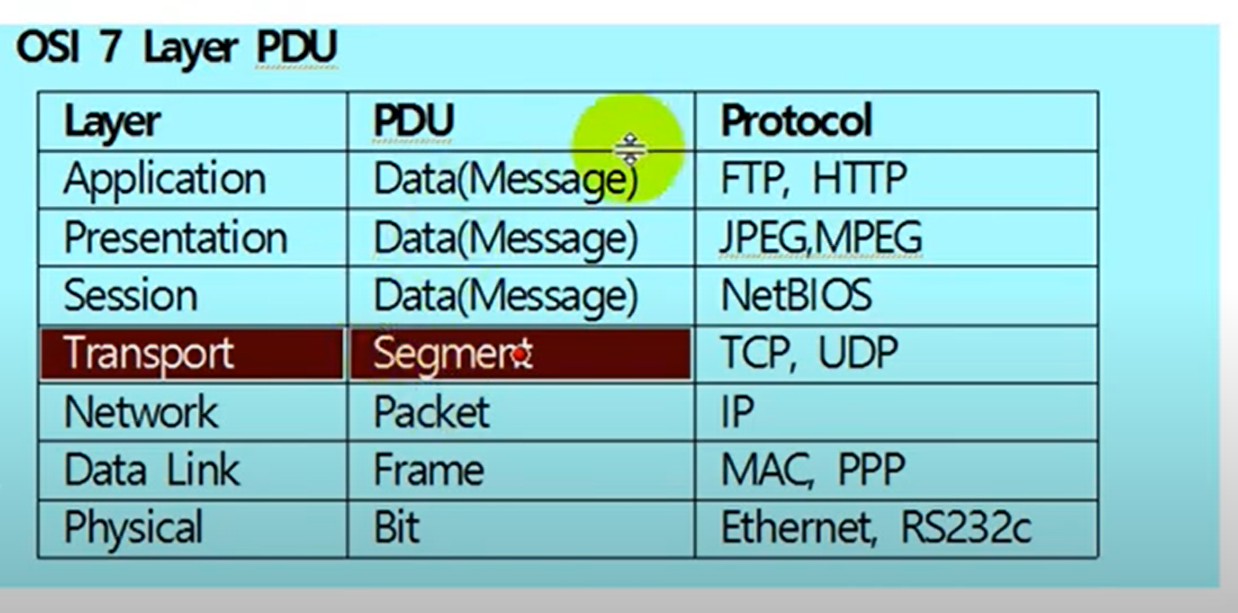
OSI 7계층 모델은 네트워크의 구조를 1계층부터 7계층까지 7단계로 구분해 개념적으로 정의한 모델입니다. 각 계층의 역할을 살며보면 다음과 같습니다. 12
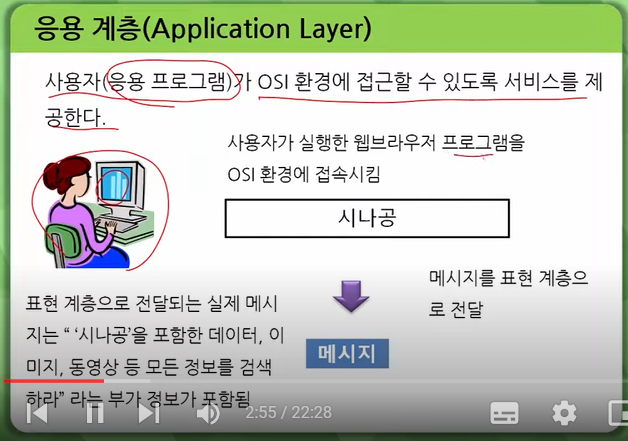
응용계층(application layer)
사용자와 직접 맞닿는 인터페이스를 제공하며, 이메일, 파일 전송, 웹 브라우저 등의 애플리케이션이 이 계층에 속합니다.
표현계층(presentation layer)
데이터의 형식을 변환하고 암호화하는 등의 기능을 담당합니다.
세션계층(session layer)
두 기기 간의 연결을 관리하고 데이터 전송 중 발생하는 오류를 복구합니다.
전송계층(transport layer)
데이터 전송의 안정성과 효율성을 보장합니다.
네트워크 계층(network layer)
경로 설정, 트래픽 제어, 패킷 전달 등의 기능을 담당합니다.
데이터링크 계층(data link layer)
물리적인 링크를 통해 데이터를 전송하고 오류를 검사합니다.
물리 계층(physical layer)
전기적, 기계적, 절차적 특성을 정의하여 실제로 데이터를 전송하는 역할을 합니다
허프만 코드(Huffman Code)는 주어진 데이터들의 출현 빈도수를 기반으로 하여 데이터 압축 및 복원 알고리즘입니다. 이 알고리즘은 데이터의 반복적인 패턴을 찾아내고 이를 간단한 이진 트리 형태로 표현함으로써 가능해집니다. 허프만 코드는 데이터 압축률이 뛰어나며 특히 텍스트나 이미지 등의 데이터에서 효과적으로 작동합니다.
데이터 수집
먼저 처리하고자 하는 데이터들을 수집하고 해당 데이터들의 출현 빈도를 계산합니다.
트리 구축
가장 빈번히 등장하는 두 개의 데이터를 부모 노드로 가지는 자식 노드를 만들고 그 다음으로 빈번한 두 개의 데이터를 선택하여 위 과정을 반복합니다.
코드 부여
만들어진 트리를 따라가며 각 데이터에 대한 코드를 부여합니다. 이때 상위 레벨의 노드로 갈수록 짧은 길이의 코드를 가지게 됩니다.
데이터 압축
실제 데이터를 압축할 때에는 허프만 코드 테이블을 만들어 두고 필요한 데이터를 해당 코드로 변환하여 저장하거나 전송합니다.
데이터 복원
압축된 데이터를 받아온 후 허프만 코드 테이블을 참고하여 원래의 데이터로 복원합니다.
허프만 코드 방식은 데이터 압축 외에도 다양한 분야에서 활용됩니다. 예를 들어 DNA 분석, 음성 인식, 동영상 압축 등에서도 사용되고 있습니다.
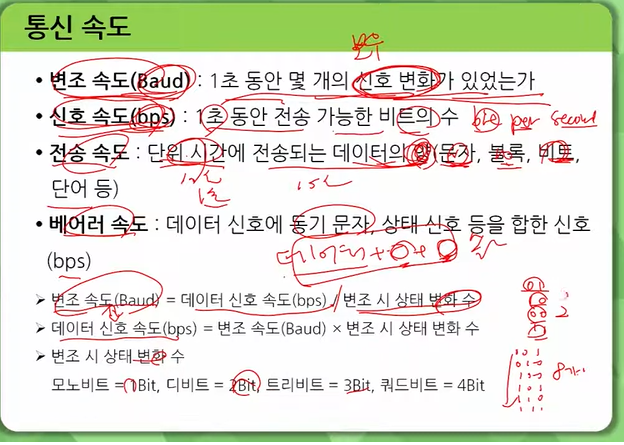
동기식 전송 방식은 양측이 동일한 타이밍을 가지고 있어 오류 발생 확률이 적고 신뢰성이 높습니다. 또 한 번에 여러 글자를 보낼 수 있으므로 전송 속도 향상에도 도움이 되며, 수신 측에서는 별도의 저장 장치 없이 받은 데이터를 그대로 사용할 수 있다는 장점이 있습니다. 1
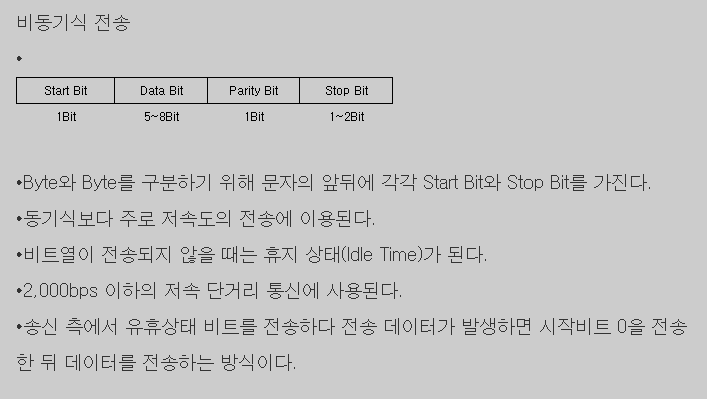
문자 동기 방식은 각 문자마다 스타트비트 (Start Bit) 와 스톱비트 (Stop Bit) 를 추가하여 하나의 프레임을 구성해 전송하는 방식으로 휴지 간격 동안 클록 신호를 이용해서 송신측과 수신측의 클럭을 동기화 시켜줍니다. 스톱비트로 문자 구분을 할 수 있습니다. 1
비트 동기 방식은 매클록마다 일정한 수의 비트를 묶어서 전송하는 방식으로서 주로 고속 직렬전송에 많이 쓰입니다.
CRC(Cyclic Redundancy Check)는 순환 중복 검사로도 불리며, 데이터 전송 중에 오류를 검출하기 위해 사용되는 오류 탐지 기술입니다. 12
발신자는 데이터와 함께 데이터로 생성한 체크섬을 발송하고, 수신자는 수신한 데이터로 체크섬을 생성하여 수신한 체크섬과 일치하는지 비교합니다. 체크섬을 생성하는 보편화된 방식 중 하나가 CRC입니다. 1
CRC는 n개의 비트로 구성되어 있으며, 패리티 비트로 사용되는 1비트, ATM이나 메모리, 정보통신망에 사용되는 8비트, CDMA에 사용되는 30비트, ECMA-182에 사용되는 64비트가 대표적입니다. 고사양의 높은 신뢰도와 빠른 속도를 원하면서 추가 전송선로 활용이 용이하다면 높은 비트의 CRC 비트를 사용하게 됩니다.
FEC(Forward Error Correction)는 피드백 경로를 필요로 하지 않는 에러 정정 기법으로, 송신 측에서 redundancy bit를 더해 메시지를 전송하며, 데이터가 손실되었을 때 bit를 바탕으로 오류를 수정합니다. 12
반면 ARQ(Automatic Repeat reQuest)는 데이터 전송 중 오류 검출 및 복구를 위한 기술로, 신뢰성이 보장되어야 하는 통신 시스템에서 많이 사용됩니다. 송신자는 데이터를 분할하여 일정한 크기의 프레임으로 나누고, 수신자는 데이터를 수신하여 CRC 등의 오류 검출 코드를 이용해 오류를 검출합니다. 오류가 검출된 경우, 수신자는 이를 송신자에게 알리고, 송신자는 이에 대한 응답을 수신자에게 보냅니다. 이를 토대로, 오류가 발생한 프레임을 재전송하거나 다음 프레임을 전송합니다.
ARQ(Automatic Repeat reQuest)는 데이터 전송 중 오류 검출 및 복구를 위한 기술로, 신뢰성이 보장되어야 하는 통신 시스템에서 많이 사용됩니다. 1
송신자는 데이터를 분할하여 일정한 크기의 프레임으로 나누고, 수신자는 데이터를 수신하여 CRC 등의 오류 검출 코드를 이용해 오류를 검출합니다. 오류가 검출된 경우, 수신자는 이를 송신자에게 알리고, 송신자는 이에 대한 응답을 수신자에게 보냅니다. 이를 토대로, 오류가 발생한 프레임을 재전송하거나 다음 프레임을 전송합니다. 1
ARQ는 수신자 피드백 방식으로 수신 측이 송신 측에 재전송을 요구하는 방식입니다. 데이터 내 첨부된 오류검출(체크섬 등) 정보로 에러 발생 유무를 점검하고, 에러가 발생한 프레임에 대해 재전송을 요구합니다. 23
종류로는 정지 대기 ARQ(Stop-and-Wait ARQ), 연속적 ARQ(Continuous ARQ), GBN(Go-back-N ARQ), Selective Repeat ARQ 등이 있습니다.
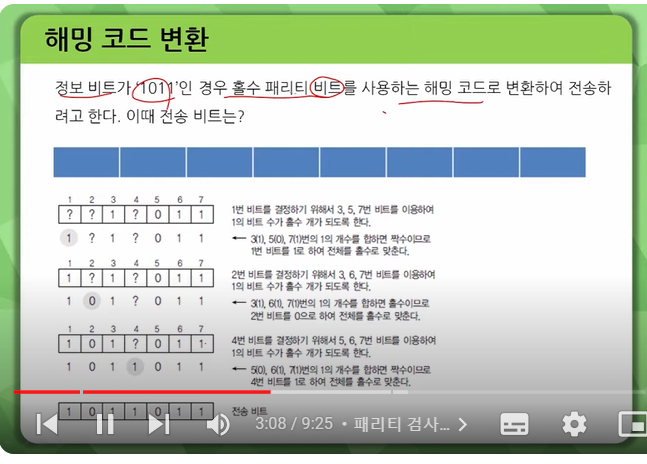
에러 검출 기법에는 패리티 검사(Parity Check), 순환 중복 검사(CRC: Cyclic Redundancy Check), 해밍 코드(Hamming Code) 등이 있습니다.
패리티 검사
가장 간단한 에러 검출 기법으로 데이터 비트들의 합을 홀수 또는 짝수가 되도록 한 비트를 추가하는 방식입니다.
순환 중복 검사(CRC)
전송된 데이터 블록에 대해 다항식으로 계산한 값을 함께 전송하여 오류를 검출하는 방식입니다.
해밍 코드
에러 정정까지 가능한 코드로, 한 비트 오류를 발견하고 동시에 교정할 수 있습니다.
HDLC(High-level Data Link Control)의 전송모드는 다음과 같습니다. 12
NRM(Normal Response Mode, 정규 응답 모드)
불균형적 링크 구성으로 주국이 세션을 열고, 종국들은 단지 응답만 하는 모드입니다. 2
ABM(Asynchronous Balanced Mode, 비동기 균형 모드)
균형적 링크 구성으로 각 국이 주국이자 종국으로 서로 대등하게 균형적으로 명령과 응답하며 동작하는 모드입니다.가장 널리 사용되며, 전이중 점대점 링크에서 가장 효과적으로 사용할 수 있습니다. 23
ARM(Asynchronous Response Mode, 비동기 응답 모드)
종국도 전송 개시할 필요가 있는 특수한 경우에 만 사용하는 모드입니다.
HDLC는 높은 수준의 데이터 링크 제어 프로토콜로서, 다음과 같은 특징을 가지고 있습니다.
프레임 형식
HDLC는 데이터를 프레임(frame) 단위로 전송합니다. 프레임은 플래그(flag), 주소(address), 제어 필드(control field), 데이터 필드(data field), 체크섬(checksum), 종료 문자(end character) 등으로 구성됩니다.
캡슐화
HDLC는 상위 계층의 데이터를 캡슐화하여 하위 계층으로 전달합니다. 즉, 상위 계층의 데이터를 프레임 안에 넣어 전송합니다.
오류 검사
HDLC는 오류 검사를 위해 체크섬(checksum)을 사용합니다. 체크섬은 데이터 필드의 내용을 요약한 값으로, 전송 중에 오류가 발생하면 이를 감지하고 수정할 수 있습니다.
흐름 제어
HDLC는 흐름 제어를 위해 폴링(polling) 방식과 웨이팅(waiting) 방식을 사용합니다. 폴링 방식은 송신자가 일정한 주기마다 수신자에게 확인 요청을 보내는 것이고, 웨이팅 방식은 수신자가 일정한 시간 동안 대기하면서 데이터를 기다리는 것입니다.
동기화
HDLC는 동기화를 위해 비트 동기화와 프레임 동기화를 사용합니다. 비트 동기화는 클럭(clock)을 통해 비트 단위로 데이터를 정렬하는 것이고, 프레임 동기화는 프레임의 시작과 끝을 나타내는 플래그를 이용해 프레임 단위로 데이터를 구분하는 것입니다.
멀티플렉싱 지원
HDLC는 멀티플렉싱(multiplexing)을 지원합니다. 이는 하나의 채널을 여러 개의 데이터 스트림이 공유하는 것을 말합니다.
보안 기능 지원
HDLC는 보안 기능을 지원합니다. 예를 들어, 암호화나 인증 기능을 추가하여 데이터의 안전성을 보장할 수 있습니다.
다양한 모드 지원
HDLC는 다양한 모드를 지원합니다. 예를 들어, 전이중 모드(full-duplex mode)와 반이중 모드(half-duplex mode)를 지원합니다.
국제 표준
HDLC는 국제 표준 기구인 ISO/IEC와 ITU-T에서 표준으로 채택되어 있으며, 많은 통신 시스템에서 사용되고 있습니다.
HDLC는 주로 유선망이나 무선망에서의 데이터 전송에 사용되며, ATM(Asynchronous Transfer Mode)이나 TCP/IP(Transmission Control Protocol/Internet Protocol) 등에서도 사용됩니다. 특히, 인터넷 전화(VoIP)에서는 음성 데이터를 HDLC 프레임으로 변환하여 전송하기도 합니다.
데이터 링크 제어 프로토콜은 데이터 링크 계층에서 사용되며, 다음과 같은 기능을 수행합니다. 1
오류 검출
오류 발생 시 이를 검출하고 수정하는 기능을 제공합니다.
흐름 제어
데이터 전송 속도를 조절하여 수신 측이 데이터를 원활하게 받을 수 있도록 합니다.
동기화
송수신 측이 동일한 시간대에서 동작할 수 있도록 동기를 맞춰줍니다.
주소 설정
송수신 측의 주소를 설정하여 데이터를 정확하게 전달할 수 있도록 합니다.
대표적인 데이터 링크 제어 프로토콜로는 HDLC(High-level Data Link Control), LLC(Logical Link Control) 등이 있습니다. 1
HDLC는 1970년대 후반 국제표준화기구(ISO)에서 표준화한 대표적인 데이터 통신 전송 제어 절차로, 정보를 전송 제어 부호가 포함된 프레임이라는 단위로 분할하여 전송합니다. 각 프레임의 시작과 끝을 8비트 부호(01111110)로 된 플래그로 감싸기 때문에 프레임의 위치는 쉽게 검출됩니다. 1
LLC는 ISO에서 제정한 LAPB(Link Access Procedure Balanced)를 개선한 프로토콜로, 오류 검출 및 수정, 흐름 제어, 동기화 등의 기능을 수행합니다. 또한, LLC는 상위 계층인 네트워크 계층과의 연동을 위한 역할도 담당합니다.
회선 접속 방식은 두 지점 사이의 데이터 전송을 위해 사용되는 기술로 다양한 방식이 존재합니다.
대표적인 회선 접속 방식으로는 다음과 같은 것들이 있습니다.
베이스밴드 방식
디지털 신호를 직접 전송하는 방식으로, 전송 속도가 빠르고 정확성이 높습니다. 하지만 고속 전송 시 케이블의 길이가 길어지면 신호의 감쇠 현상이 심해져 장거리 전송에는 부적합합니다.
브로드밴드 방식
디지털 신호를 아날로그 신호로 변환하여 전송하는 방식으로, 베이스밴드 방식보다 전송 거리가 길다는 장점이 있습니다. 하지만 전송 과정에서 신호의 손상이 일어날 수 있으므로, 이를 보완하기 위한 기술이 필요합니다.
직렬 방식
하나의 선로를 이용해 한 번에 한 비트씩 전송하는 방식으로, 전송 속도가 느리지만 안정성이 높다는 장점이 있습니다.
병렬 방식
여러 개의 선로를 이용해 한 번에 여러 비트씩 전송하는 방식으로, 전송 속도가 빠르지만 선로가 복잡해지고 비용이 많이 든다는 단점이 있습니다.
회선 접속 방식에는 다음과 같은 종류가 있습니다.
점대점(Point to Point)
두 대의 단말 장치 사이를 직접 연결하는 방식입니다.
교환 방식
데이터 통신에서 여러 개의 단말 장치가 서로 통신할 때, 한 번에 하나의 단말 장치만 상대방과 통신할 수 있는 방식입니다.
다중점 방식(Multipoint)
여러 대의 단말 장치가 하나의 회선에 동시에 접속하여 통신하는 방식입니다.
비동기 전송 방식(ATM)
디지털 전송 기술 중 하나로, 고속 통신에 사용됩니다.
프레임 릴레이(Frame Relay)
전용회선 방식의 일종으로, 데이터 프레임 단위로 전송하는 방식입니다.
셀룰러 방식(Cellular)
이동통신에서 사용되는 방식으로, 기지국과 이동국 사이에서 음성이나 데이터를 셀이라는 작은 단위로 나누어 전송하는 방식입니다.
무선랜(WLAN)
무선으로 인터넷에 접속하는 기술로, 유선 랜과 달리 선 없이도 인터넷을 이용할 수 있습니다.
위성통신
위성을 통해 지구 전역에서 통신을 할 수 있는 시스템입니다.
광섬유 케이블
유리나 플라스틱 섬유를 이용해 만든 케이블로 전기 신호 대신 빛을 이용하므로 속도가 빠르고 안정성이 높습니다.
통신 방식은 크게 단방향 통신, 반양방향 통신, 양방향 통신으로 나눌 수 있습니다. 12
단방향 통신
데이터를 전송하는 방향이 단방향인 것을 말합니다. 12
반양방향 통신
전송의 방향은 양방향이지만 전송이 이루어지는 한 순간에는 양쪽 중 한 방향만으로 전송이 가능한 것을 말합니다. 12
양방향 통신
동시에 양방향 전송이 가능한 것을 말하며, 데이터를 수신하고 있는 동안에도 보내고 싶은 데이터를 송신할 수 있어 전송 능률이 높습니다.
동기식 전송 방식과 비동기식 전송 방식은 데이터 전송 방식에 따른 구분 방법입니다. 12
동기식 전송 방식
데이터를 송수신할 때 동기를 맞추기 위해 특정한 제어 신호를 사용하는 방식입니다. 일정한 길이의 데이터 블록을 한 묶음으로 만들어 전송하며, 미리 정해진 규칙에 따라 데이터를 전달합니다. 대표적으로 비트 지향형과 문자 지향형이 있습니다. 2
비동기식 전송 방식
송신 측에서 데이터를 보내는 시점과 수신 측에서 데이터를 받는 시점이 서로 일치하지 않는 방식입니다. 데이터 전송 중간에 오류가 발생하더라도 자동으로 오류를 수정하여 재전송할 수 있습니다. 대표적으로 ATM이 있습니다
나이퀴스트(Nyquist)공식은 다음과 같습니다.
잡음과 왜곡이 없는 이상적인 채널에서의 최대 전송율을 정의
무잡음 채널에서 채널용량은 전송채널의 대역폭 제한을 받음
C = 2Blog2 M[bps] (C= 채널용량, B=전송 채널의 대역폭, M:진수)
예를 들어, 약 3300Hz의 대역폭을 가지는 전화 시스템의 채널 용량은 다음과 같이 구할 수 있습니다.
채널 용량 = 2 ×3300 ×log2(2)bps = 2 ×3300bps = 6600bps
이론적 최대 채널의 용량이지만 여러 잡음, 왜곡 등으로 실제 채널 용량은 낮을 수 있습니다.
샤논의 법칙은 정보 이론에서 채널 용량을 계산하는데 사용되는 수학적 공식입니다. 이 법칙은 1948년 클로드 샤논이 발표하였으며 다음과 같이 나타낼 수 있습니다.
C = Wlog_2(1 + SNR) (bps)
여기서 C는 채널 용량, W는 채널의 대역폭, 그리고 SNR은 신호 대 노이즈 비율입니다. 이 공식은 채널에서 최대한 많은 정보를 전송할 수 있는 능력을 나타냅니다. 즉, 채널의 대역폭과 신호 대 노이즈 비율이 높을수록 더 많은 정보를 전송할 수 있다는 것을 의미합니다.
예를 들어, 1MHz의 대역폭을 가진 채널에서 신호 대 노이즈 비율이 10dB인 경우, 채널 용량은 약 3Mbps가 됩니다. 그러나 동일한 채널에서 신호 대 노이즈 비율이 0dB인 경우, 채널 용량은 약 0.5Mbps로 감소합니다. 이것은 샤논의 법칙이 왜 중요한지 보여주는 좋은 예입니다. 즉, 채널의 성능을 개선하려면 채널의 대역폭을 늘리거나 신호 대 노이즈 비율을 높여야 한다는 것을 알 수 있습니다.
결론적으로, 샤논의 법칙은 정보 이론에서 매우 중요한 개념 중 하나로, 채널 용량을 계산하는 데 있어서 필수적인 도구입니다. 이 법칙을 이용하면 채널의 성능을 분석하고 개선하는 데 큰 도움이 됩니다.
채널 용량은 정해진 오류 발생률 내에서 채널을 통해 최대로 전송할 수 있는 정보의 양으로, 측정 단위는 초당 전송되는 비트의 수가 됩니다. 1
나이퀴스트( Nyquist)공식
잡음과 왜곡이 없는 이상적인 채널에서의 최대 전송율을 정의합니다.
샤논(Shannon)의 정리
신호대 잡음비와 관련시켜 채널의 최대 용량을 구하는 공식입니다.
채널 용량 공식
C=BW log2(1+S/N)bps 1
C: 채널 용량, B: 대역폭, S/N: 신호대 잡음비
전자 통신 시스템에서 정보를 전달하는 과정은 여러 요소에 의해 영향을 받으며, 이러한 과정에서 '전송'은 핵심 역할을 수행합니다. 정보를 전달하는 과정에서 생기는 잡음이나 간섭을 최소화하고, 신호를 목적지로 정확하게 전송하기 위해서는 효율적인 전송 방식과 설정이 필요합니다. 1
전송 과정에서 가장 중요한 요소 중 하나는 '연속성'이며, 이는 정보가 중간에 끊기거나 손실되지 않고 일관되게 전송되는 것을 의미합니다. 이를 위해 전송된 정보가 수신 측에서 올바르게 해석되고 처리될 수 있도록 해야 하며, 효율적인 전송과 설정을 위해서는 전문 용어와 기술적인 지식이 필요합니다. 1
첫째로, '프로토콜'은 통신에 사용되는 규칙과 규약을 정의하며, 이를 통해 통신 장비 간에 상호 작용이 원활하게 이루어질 수 있습니다. 둘째로, '밴드폭'은 단위 시간당 전송 가능한 데이터 양을 의미하며, 충분한 밴드폭을 확보함으로써 정보 전송의 속도와 효율성을 높일 수 있습니다. 1
이러한 전문 용어와 기술적인 지식을 바탕으로 효율적인 전송과 설정을 위한 방법을 연구하고 개발해 나가는 것이 중요합니다. 예를 들어, 신호 간 간섭을 줄이는 기술이나, 데이터 압축 기술 등을 활용하여 전송 효율을 높이는 것이 가능합니다. 또한, 전송 환경에 따라 적절한 전송 방식을 선택하고 최적화하는 것도 중요합니다
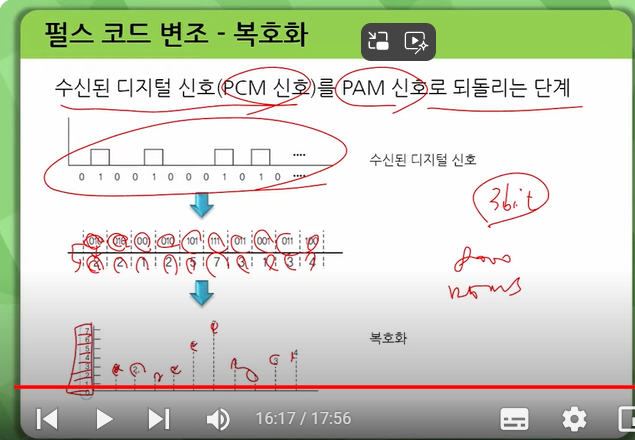
표본화, 양자화, 부호화, 복호화에 대해 알려드리겠습니다.
표본화
연속적인 아날로그 신호를 디지털 신호로 변환하기 위해 일정한 간격으로 신호를 추출하는 과정입니다. 1
양자화
추출한 신호의 크기를 유한한 개수의 값으로 표현하는 과정입니다.
부호화
양자화된 신호를 이진수열로 나타내는 과정입니다.
복호화
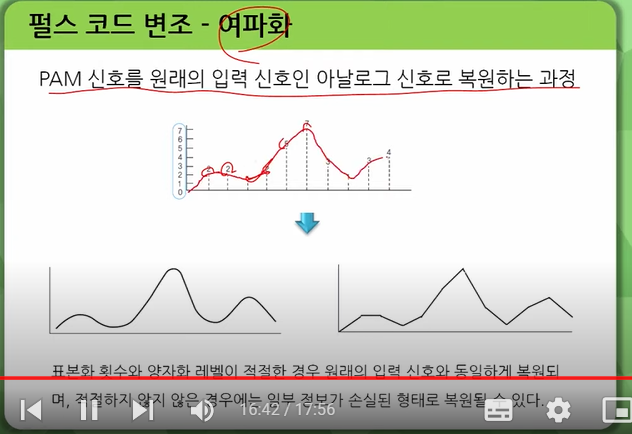
부호화된 디지털 신호를 원래의 아날로그 신호로 되돌리는 과정입니다.
PCM(Pulse Code Modulation)은 아날로그 신호를 디지털로 변환하는 기본 변조방식으로 장거리 전송을 목적으로 하기보다는 정보를 가공하는 것을 목적으로 하는 신호처리의 개념입니다. 1
PCM 변조를 위해서는 표본화, 양자화, 부호화의 과정을 거치며, DPCM (차분 펄스 부호변조)은 PCM과 달리 절대적인 값으로 부호화하는 것이 아니라 바로 전데이터와의 차이만을 부호화하는 방식으로 고효율 PCM이라 합니다
디지털 전송(Digital Transmission)은 디지털 형태로 변환된 정보를 전기 신호로 바꾸어 전송하는 방식을 말합니다.
디지털 전송은 다음과 같은 특징을 가지고 있습니다. 1
보안성
암호화 기술을 이용하여 정보를 보호할 수 있어 보안성이 높습니다.
정확성
정보의 손실이나 왜곡이 적어 정확한 정보를 전달할 수 있습니다.
대용량 전송
대량의 정보를 빠르게 전송할 수 있습니다.
다양한 매체 이용
다양한 매체를 이용하여 정보를 전송할 수 있습니다. 23
디지털 전송 방식에는 USB, 블루투스, 와이파이, LTE 등이 있습니다
아날로그 전송은 디지털 전송과는 달리 신호를 보내는 쪽과 받는 쪽의 규격이 일치하지 않아도 전송이 가능하다는 장점이 있습니다. 이 때문에 과거에는 대부분의 통신이 아날로그 방식으로 이루어졌습니다. 하지만 아날로그 전송은 신호의 왜곡이나 손실이 발생할 가능성이 높고, 보안성이 취약하다는 단점이 있습니다.
최근에는 디지털 전송이 보편화되면서, 아날로그 전송은 일부 분야에서만 사용되고 있습니다. 예를 들어, 대용량 데이터의 고속 전송을 위한 케이블TV나 광섬유 통신에서는 여전히 아날로그 전송이 사용되고 있습니다.
하지만 최근에는 아날로그 전송의 단점을 보완하면서도 디지털 전송의 장점을 결합한 새로운 방식의 전송 기술이 개발되고 있습니다. 예를 들어, 아날로그 신호를 디지털 신호로 변환하여 전송한 후 다시 아날로그 신호로 복원하는 방식의 기술이 개발되고 있습니다. 이러한 기술은 디지털 전송의 보안성과 효율성을 유지하면서도 아날로그 전송의 유연성과 호환성을 제공할 수 있어서 미래의 통신 기술로 주목받고 있습니다.
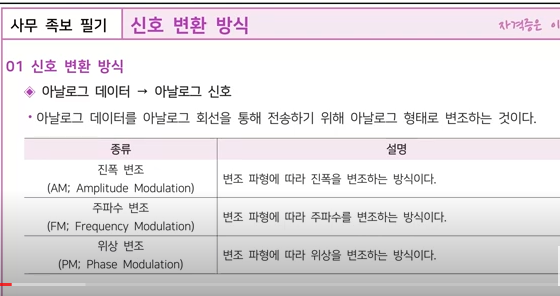
아날로그 신호를 디지털 신호로 바꾸는 과정을 말하며, 음성, 영상 등의 신호를 디지털 형식으로 저장하거나 전송하기 위해 필수적인 기술입니다.
아날로그 부호화의 종류로는 표본화, 양자화, 부호화가 있습니다.
표본화는 연속적인 아날로그 신호를 일정한 시간 간격으로 추출하여 이산적인 값으로 표현하는 과정입니다. 양자화는 표본화된 값을 유한한 개수의 정수 값으로 근사시키는 과정이며, 부호화는 양자화된 값을 2진수로 표현하는 과정입니다.
대표적인 아날로그 부호화 방식으로는 PCM(Pulse Code Modulation), DPCM(Differential Pulse Code Modulation), ADPCM(Adaptive Differential Pulse Code Modulation) 등이 있습니다.
정보 전송 형태는 다음과 같습니다. 12
단방향 전송: 한쪽 방향으로만 정보를 전달하는 방식으로, 라디오, TV 등이 대표적인 예입니다.
반이중 전송: 양쪽 방향으로 정보를 전달할 수 있지만, 동시에 전달할 수는 없는 방식입니다. 무전기가 대표적인 예입니다.
전이중 전송: 양쪽 방향으로 정보를 동시에 전달할 수 있는 방식입니다. 전화 통화가 대표적인 예입니다.
비동기식 전송: 한 문자와 같이 비교적 적은 데이터의 앞과 뒤에 각각 시작(Start) 비트와 끝(Stop) 비트를 첨가하여 전송하는 방식입니다. 통신을 하지 않는 경우는 휴지 상태로 0값을 유지하며, 시작 비트는 1로 시작하여 전송시작을 표시하고 스톱 비트는 00을 가집니다. 34
동기식 전송: 여러 문자를 한 번에 전송하므로 버퍼 장치가 필요하며 위상 편이 변조(PSK)를 이용하여 빠른 전송속도에서 이용됩니다. 문자 동기는 제어 문자를 통해 동기화(SYN) 하며, 비트 동기는 특수 비트를 통해 동기화(0110) 합니다.
정보통신 접속장비에는 다음과 같은 것들이 있습니다.
허브(Hub)
여러 대의 컴퓨터를 연결하여 데이터를 전송할 수 있도록 해주는 장치입니다.
브리지(Bridge)
두 개의 근거리통신망을 연결 하여 하나의 망으로 통합하는 장치입니다.
라우터 (Router)
여러 개의 네트워크를 연결하여 데이터를 주고받을 수 있도록 해주는 장치입니다.
모뎀(MODEM)
디지털 신호를 아날로그 신호로 변환하거나, 반대로 아날로그 신호를 디지털 신호로 변환해 주는 장치입니다.
게이트웨이(Gateway)
서로 다른 프로토콜을 사용하는 네트워크를 연결 해 주는 장치입니다.
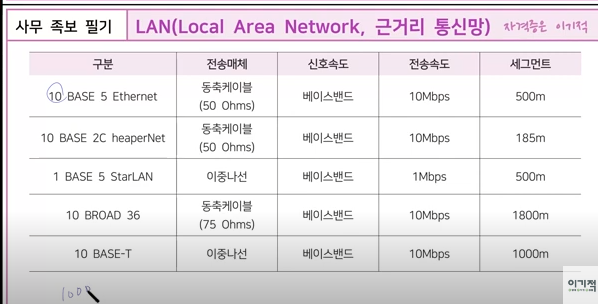
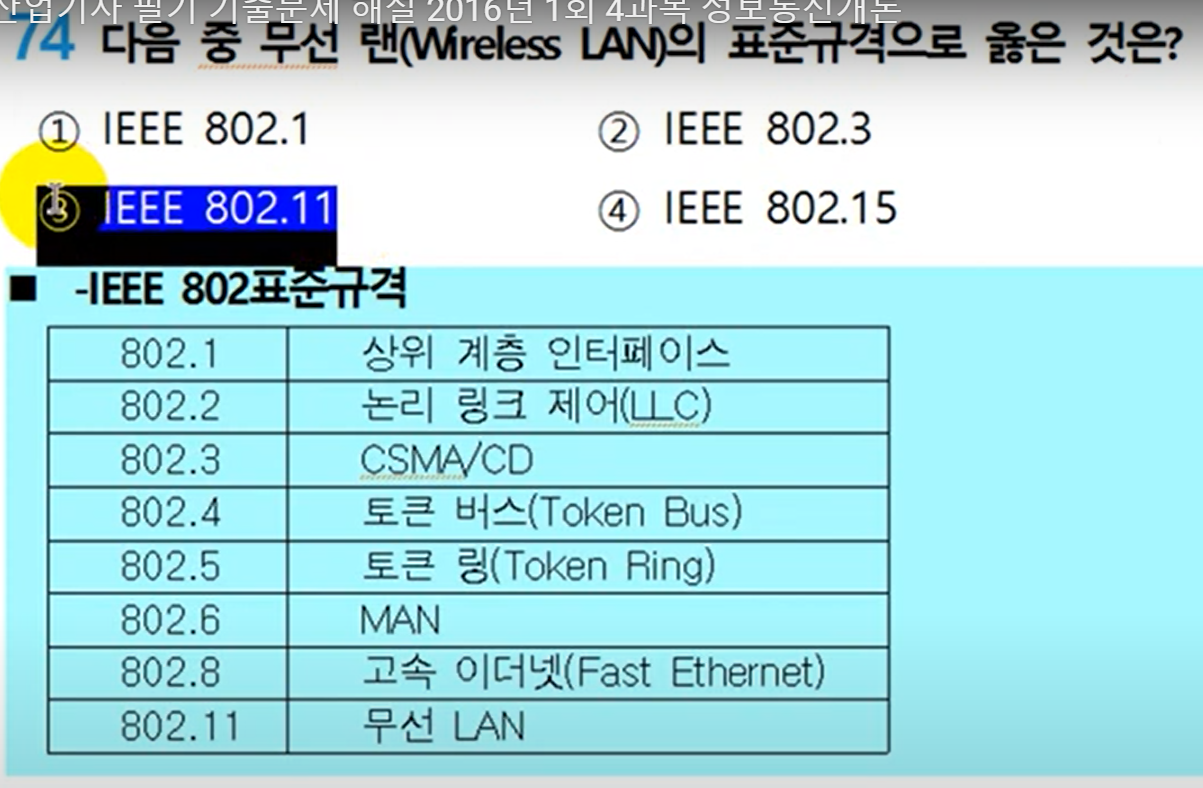
LAN은 근거리 통신망의 약자로, 지역적인 범위 내에서 데이터 통신을 가능하게 하는 네트워크 시스템입니다. 12
주로 사무실, 학교, 가정 등에서 사용되며, 건물 내부나 근처의 건물들 사이에 설치됩니다. 이 네트워크는 사용자들이 파일, 프린터, 인터넷 연결 등의 자원을 공유할 수 있게 합니다
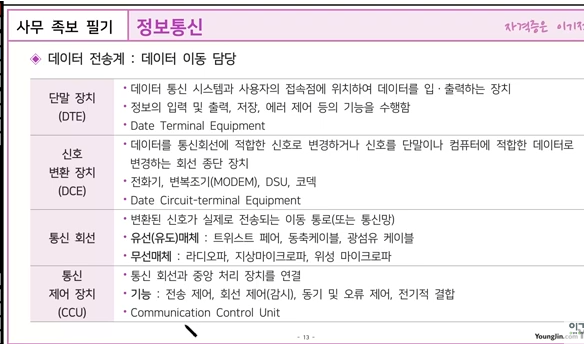
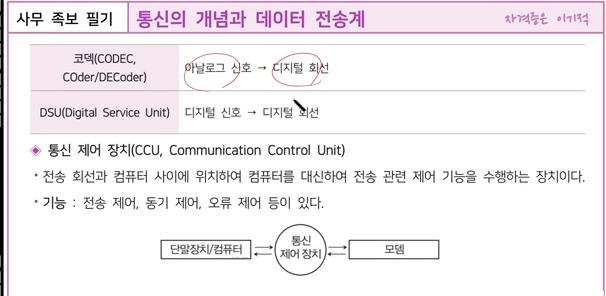
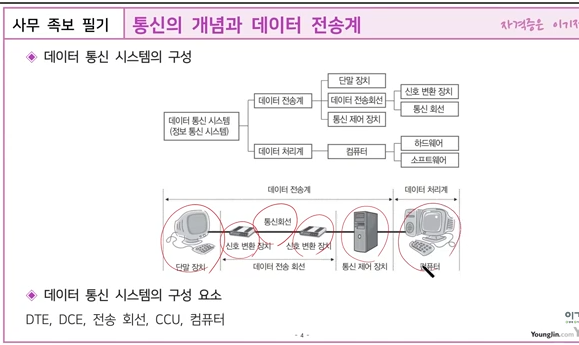
통신 제어 장치(CCU)는 온라인 데이터 통신 시스템에서 주 컴퓨터에 접속되어 주 컴퓨터와 단말 간 또는 다른 주 컴퓨터 간에 통신 제어 기능을 수행하는 장치입니다. 1
통신 제어 장치는 다음과 같은 기능을 수행합니다. 1
전송 제어
통신 제어 장치는 전송 제어 전용 장치이며 통신 회선은 주 컴퓨터와 접속되는 것이 아니라 통신 제어 장치와 접속됩니다. 1
오류 검사
실제로 데이터를 송수신하고 전송 오류를 검사합니다. 1
흐름 제어
통신 제어 작업으로부터 주 컴퓨터를 해방시켜 줌으로써, 주 컴퓨터의 처리 시간을 효율적으로 이용할 수 있게 합니다.
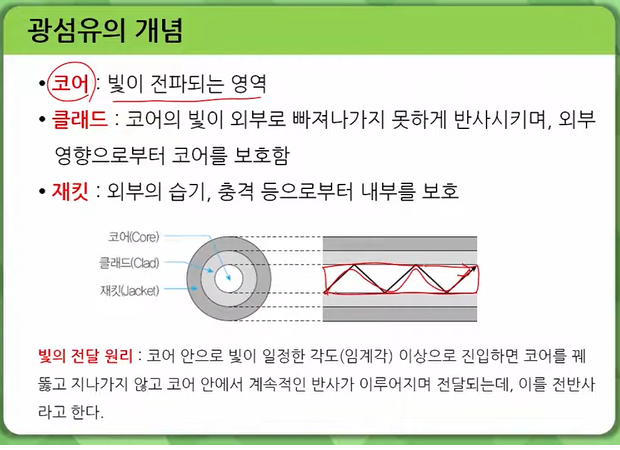
광섬유 케이블은 광섬유를 이용한 하나의 통신 매체로, 빛을 이용하는 통신 방식이기 때문에 전기신호를 사용하는 통신방식보다 자료 전송속도가 수십 배로 빠릅니다. 이를 위해 FTTH방식의 네트워크를 새로 구축해야 합니다. 12
광섬유 케이블은 동선 케이블에 비해 손실이 적기 때문에 중계기 간격이 수십 km 이상 100km 정도까지 가능하며, 부피가 작고 가벼운 광섬유는 모재(母材)로부터 100km 이상 생산하여 케이블화할 수 있습니다. 3
또한, 광섬유 케이블은 일반적인 기존의 구리 선 등 다른 유선 전송 매체보다 대역폭이 넓어 데이터 전송률이 뛰어나다는 것 또한 특징입니다. 광섬유 케이블의 HS Code를 살펴보면, 크게는 ‘절연 전선, 케이블 및 기타 절연 전도체, 광섬유 케이블(Insulated wire, cable and other insulated electric conductors, optical fiber cables)’을 포괄하는 제8544호에 속하며 세부적으로는 ‘광섬유 케이블(Optical fiber cables)’로 정의된 8544.70으로 분류됩니다
동축케이블은 케이블 TV, 인터넷, 전화 등의 통신 선로로 사용되며, 구리나 알루미늄으로 된 전선에 절연체를 씌워 만든 케이블입니다.
주로 건물 내부나 지하 등의 단거리 통신에 사용되며, 외부 환경에 노출되는 경우에는 보호 피복이 필요합니다. 또한, 다른 종류의 케이블보다 전송 손실이 적고, 고속 통신이 가능하다는 장점이 있습니다. 하지만, 거리가 멀어질수록 신호의 세기가 약해지고, 노이즈가 발생할 수 있다는 단점이 있습니다. 최근에는 광섬유 케이블이 대체재로 많이 사용되고 있습니다.
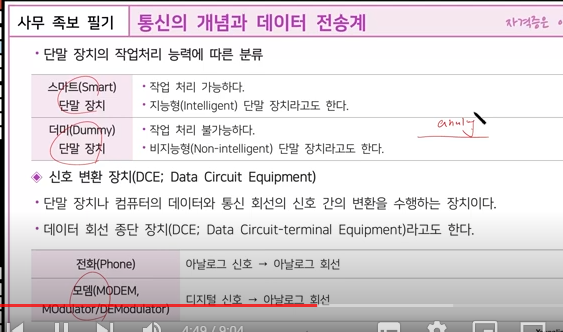
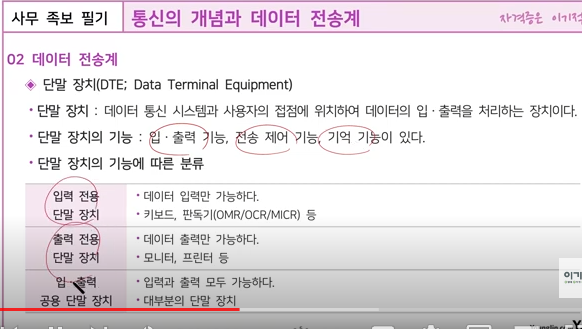
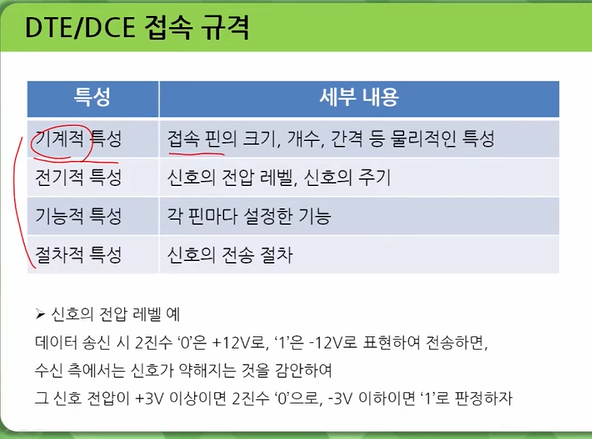
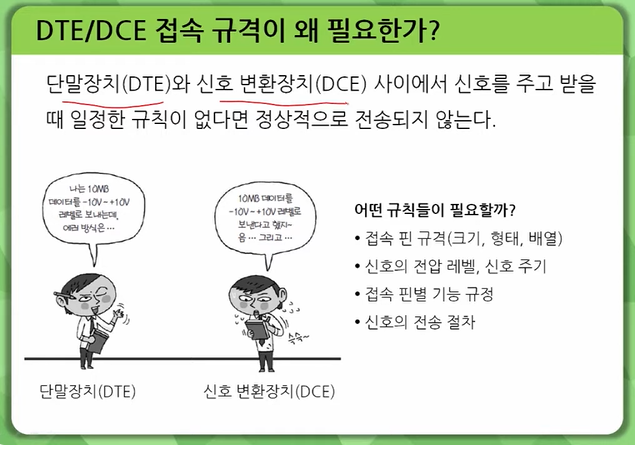
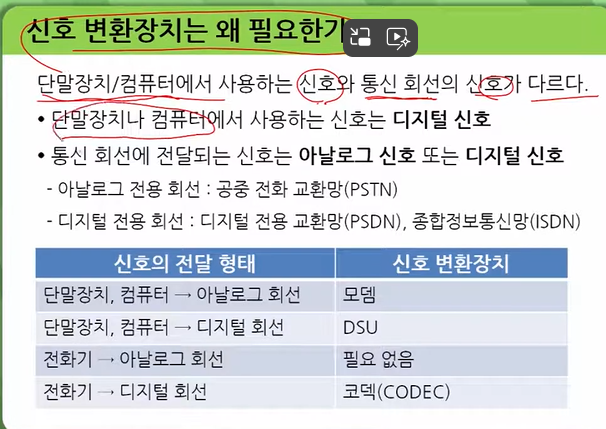
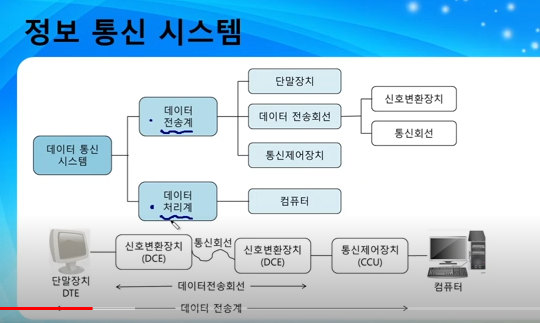
DCE(Data Circuit Equipment)는 데이터 신호 변환 장치를 의미하며, DTE(Data Terminal Equipment)는 데이터 단말 장치를 의미합니다. 1
DCE는 데이터 통신 장비로서, 네트워크 측으로 구성되는 통신 네트워크 장비의 연결 수단 역할을 담당하는 연결 통로를 제공해줍니다. 대표적인 예로는 모뎀(DSU/CSU)과 케이블이 있습니다. 2
DTE는 사용자 측에서 데이터 송신이나 수신의 용도로 사용되는 장비입니다. 대표적인 예로는 PC, 라우터 등이 있습니다.
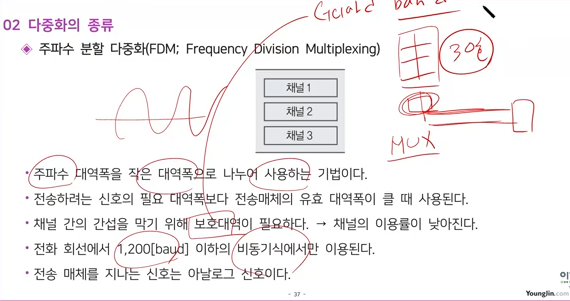
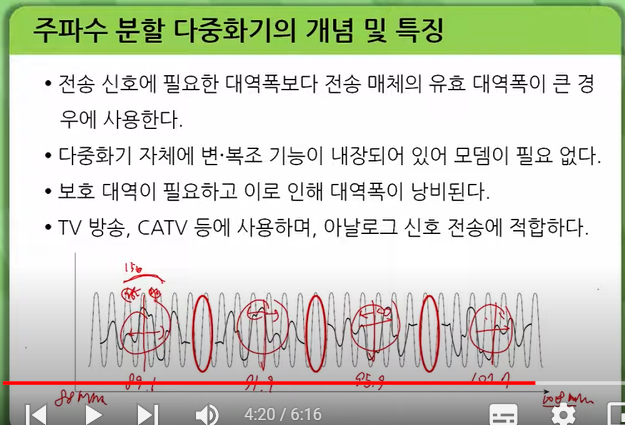
주파수 분할 다중화(FDM)는 하나의 전송로에 여러 개의 주파수 채널을 할당하여 데이터를 동시에 전송하는 기술입니다. 각 채널은 서로 다른 주파수 대역을 사용하며, 각각의 데이터 신호는 해당 채널의 주파수 대역에서만 전달됩니다.
이는 기존의 단일 반송파 통신 방식에서 한 번에 하나의 데이터만 전송할 수 있는 것과는 달리, 여러 개의 데이터를 동시에 전송할 수 있기 때문에 전송 속도를 높일 수 있습니다. 또한, 각 채널의 주파수 대역폭을 조절하여 데이터의 전송 속도를 조절할 수도 있습니다.
하지만 FDM은 인접한 채널 간의 간섭이 발생할 수 있으며, 이를 방지하기 위해 보호대역이 필요합니다. 이는 주파수 자원의 낭비를 초래할 수 있습니다. 또한, 고속의 데이터 전송에는 적합하지 않습니다. 이러한 단점을 보완하기 위해 등장한 기술이 시분할 다중화(TDM)와 직교 주파수 분할 다중화(OFDM)입니다.
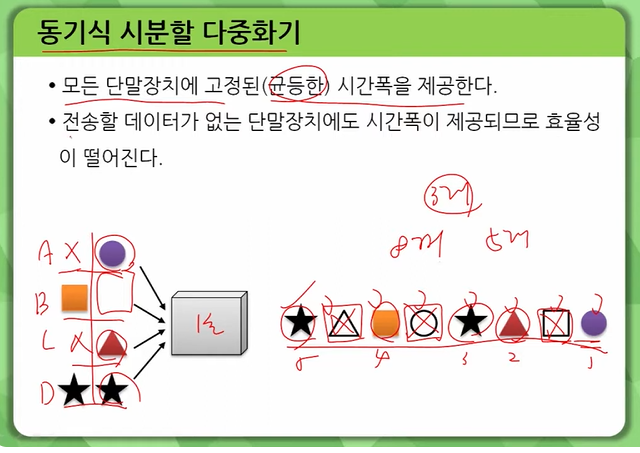
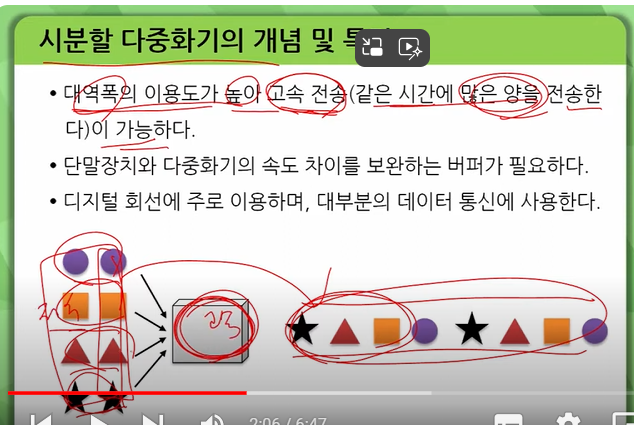
다중화는 하나의 회선 또는 전송로를 분할하여 개별적으로 독립된 신호를 동시에 송수신할 수 있는 다수의 통신로를 구성하는 기술입니다. 대표적인 다중화 방식으로는 주파수 분할 다중 방식(FDM)과 시분할 다중 방식(TDM) 등이 있습니다. 12
주파수 분할 다중화(FDM)
하나의 회선을 다수의 주파수 대역으로 분할하여 다중화하는 방식입니다. 12
시분할 다중화(TDM)
하나의 회선을 다수의 아주 짧은 시간 간격으로 분할하여 다중화하는 방식입니다.
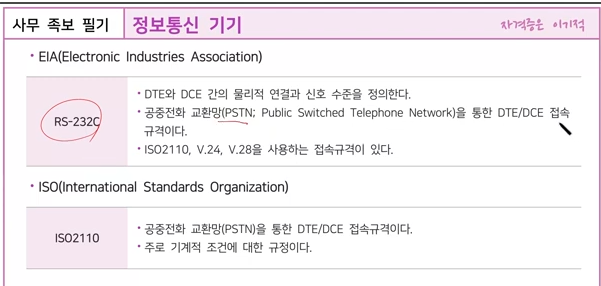
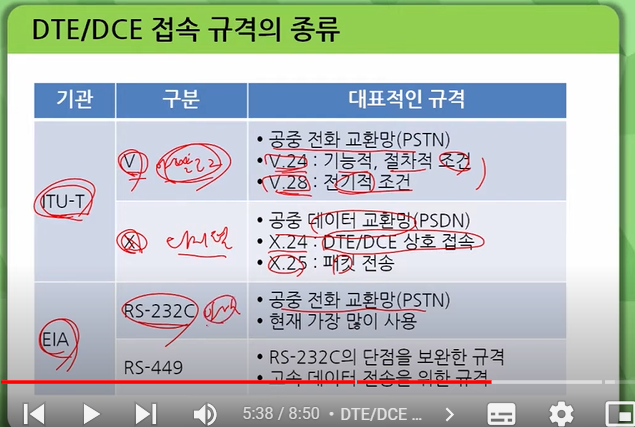
미국전자공업협회(EIA)가 제정하여 권고하거나 추장하는 표준을 EIA-RS라고 하며, RS가 미국표준협회(ANSI)에 의하여 표준으로 채택되면 ANSI/ EIA 표준이라고도 합니다. 1
잘 알려진 표준으로는 컴퓨터와 주변 장치 또는 데이터 단말 장치(DTE)와 데이터 회선 종단 장치(DCE)를 상호 접속하기 위한 인터페이스 표준 규격인 RS-232C, RS-422, RS-423, RS-530 등이 있습니다.
HFC(Hybrid Fiber Coax)는 광동축 혼합망으로, 케이블TV 방송사에서 초고속 인터넷 서비스를 제공할 때 사용하는 기술입니다. 이 기술은 광섬유와 동축 케이블을 함께 사용하여 대용량의 데이터를 고속으로 전송할 수 있습니다. 1
HFC망은 다음과 같은 구성 요소로 이루어져 있습니다. 1
광전송장치
광송신기는 분배센터의 전기 신호를 광신호로 변환하여 ONU로 송신하며, 광수신기는 분배센터에서 ONU 광신호를 전기 신호로 변환하여 수신합니다.
옥외광송수신기(ONU)
Cell의 중심으로서 상·하향 광과 RF 신호 간 변환을 담당합니다. 1
광케이블
SO에서 ONU까지의 전송로에 사용됩니다.
동축전송장치
증폭기는 동축 케이블의 선로 신호 손실을 보상하며, 분배기는 하나의 RF 신호를 다수의 채널로 나누어 전달합니다. 1
HFC망의 장점으로는 최고 10Mbps의 초고속 인터넷 서비스를 제공할 수 있다는 점이 있습니다
VoIP(Voice over Internet Protocol)는 인터넷을 통해 음성 통신을 가능하게 하는 기술입니다. 이는 전통적인 전화 회선을 사용하는 것과는 다른 방식으로 작동합니다. 음성 통화는 Internet을 통해 전송되고, 통화 내용은 디지털 신호로 변환되어 전송됩니다. 이러한 기술은 전 세계적으로 널리 사용되고 있으며, 많은 기업과 개인들이 이를 통해 비용을 절감하고 효율적인 음성 통신을 이루고 있습니다. 12
기술적으로 전송 제어 프로토콜 또는 인터넷 프로토콜을 사용하여 음성 데이터를 패킷으로 분할하고 인터넷을 통해 전송하는 것으로 작동합니다. 이러한 패킷은 네트워크를 통해 전송되고, 받는 쪽에서는 해당 패킷을 복원하여 음성으로 재구성합니다. 이러한 프로세스는 일반적으로 실시간으로 이루어지며, 음성 데이터의 지연이 최소화되도록 설계되었습니다. IP 네트워크를 기반으로 작동하기 때문에, 기존의 전화 회선과는 달리 추가 하드웨어가 필요하지 않습니다. 사용자는 Internet에 연결된 컴퓨터, 스마트폰 또는 전화기를 통해 서비스를 이용할 수 있습니다. 이렇게 하면 전화...
VPN(가상 사설망)은 개인이나 기업이 데이터나 신원을 보호할 때 사용되는 기술입니다. VPN은 IP 주소를 차단하고 다른 곳으로 돌리는 방식으로 작동하기 때문에, 나의 데이터나 브라우징 기록에 누군가가 접근하는 것을 막을 수 있고, 거주 지역에서 접속할 수 없는 웹사이트나 서비스를 이용하고자 할 때 사용하면 유용합니다. VPN은 특히 공용 무선 인터넷을 이용할 때 정부 기관이나 해커에 대항할 수 있는 보안의 막이 되어주기도 하며, 회사 직원들이 사무실 밖에서 회사 자료에 안전하게 접근할 수 있도록 해주는 기능도 있습니다. 현재 무료 혹은 유료로 사용할 수 있는 VPN 서비스들이 많이 출시되어 있으며, VPN은 컴퓨터나 태블릿, 심지어 스마트폰에 소프트웨어를 설치한 후 쉽게 사용할 수 있습니다.
ADSL은 Asymmetric Digital Subscriber Line의 약자로, 디지털 가입자 회선의 한 형태입니다. 이 기술은 주로 가정이나 소규모 사업장에서 인터넷 액세스에 사용됩니다. ADSL은 전화 회선을 통해 빠르고 안정적인 인터넷 연결을 제공합니다. 12
이러한 기술의 특징 중 하나는 비대칭성입니다. 즉, 다운로드 속도가 업로드 속도보다 빠릅니다. 이는 대부분의 사용자가 인터넷에서 콘텐츠를 다운로드하는 데 더 많은 대역폭을 필요로 하기 때문에 필요한 조치입니다. 그러나 이것은 송신과 수신 간 데이터 전송의 불균형을 의미하기도 합니다.
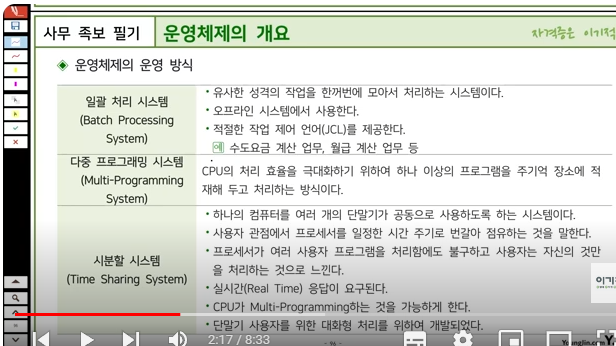
배치 처리(batch processing)와 일괄 처리는 비슷한 개념이지만 약간의 차이가 있습니다.
배치 처리
대용량 데이터를 모아두고 특정 시점이나 주기마다 한 번에 처리하는 방법입니다. 예를 들어 하루 일과가 끝난 후 밤에 어제 발생한 거래 내역을 한꺼번에 정산하는 경우나 월말에 지난 달의 매출액을 계산하는 경우 등이 해당됩니다. 이러한 작업들은 시스템 자원을 많이 소모하고 대기 시간이 길어져 실시간성이 떨어지는 문제가 있습니다.
일괄 처리
하나의 작업 단위로 묶어 일련의 과정을 거쳐 처리하는 방식입니다. 주로 파일 처리나 데이터베이스 관리 등에서 사용되며, 대량의 데이터를 효율적으로 처리할 수 있지만 작업 완료까지 시간이 오래 걸리는 단점이 있습니다.
요약하면, 배치처리는 일정 기간동안 쌓인 데이터를 모아서 한번에 처리하는 방식이며, 일괄처리는 하나의 작업 단위로 묶어서 처리하는 방식입니다. 두 가지 방식 모두 대규모 데이터를 처리하는데 유용하지만, 실시간성이 떨어지거나 작업 완료까지의 시간이 오래 걸린다는 단점이 있습니다.
시분할처리(TSS: Time Sharing System)는 컴퓨터의 중앙처리장치를 여러 개의 단말기에 접속하고 시분할 방식에 의해 중앙처리장치의 기능을 고객에게 제공하는 서비스입니다. 1
하나의 컴퓨터를 여러 명의 사용자가 동시에 사용하는 것처럼 보이게 하는 기술로, 각각의 사용자는 일정한 시간 동안 CPU를 독점하여 자신의 프로그램을 실행할 수 있습니다.
CPU 사용 시간을 잘게 나누어 여러 사용자에게 배분하므로 모든 사용자는 마치 자신만이 컴퓨터를 독점하여 사용하는 것처럼 느끼게 됩니다.
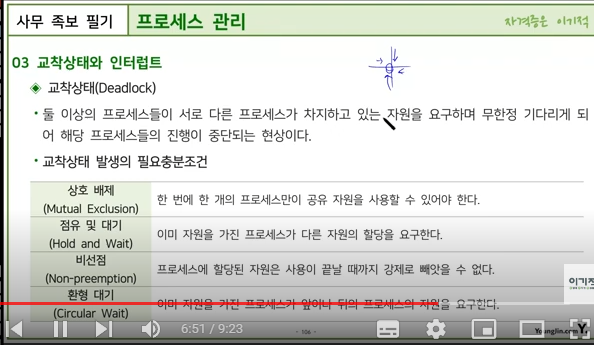
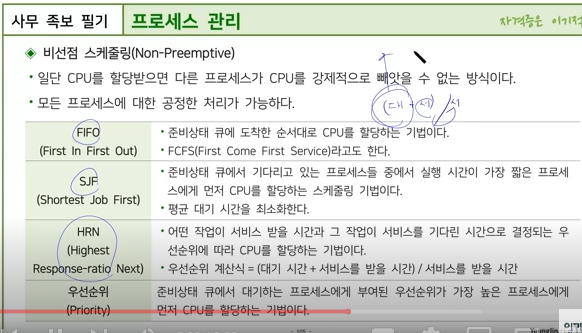
비선점형 스케줄링은 프로세스가 중앙처리장치를 할당받게 되었을 때 그 프로세스가 종료되거나 자발적으로 중지되지 않는 한 계속해서 실행이 가능한 방식입니다. 이 방식은 정해진 순서대로 처리되므로 공정성을 보장하며, 다음에 어떤 프로세스가 오더라도 응답 시간을 예측할 수 있다는 장점이 있습니다. 1
대표적인 비선점형 스케줄링 알고리즘으로는 FCFS(First Come First Served), SJF(Shortest Job First), HRN(Highest Response ratio Next) 등이 있습니다.
FCFS
가장 먼저 도착한 프로세스에게 우선순위를 부여하는 방식입니다. 간단하면서도 공정한 방식이지만, 긴 작업이 짧은 작업을 기다리는 경우 전체 시스템의 성능이 저하될 수 있습니다.
SJF
작업의 길이가 짧을수록 우선순위를 높게 부여하는 방식입니다. 평균 대기 시간이 짧아져 시스템의 성능이 높아지지만, 짧은 작업이 많은 경우에는 오히려 시스템의 성능이 저하될 수 있습니다.
HRN
SJF의 문제점을 보완한 방식으로, 우선순위 계산 시 현재까지의 대기 시간뿐만 아니라 미래의 대기 시간까지 고려합니다.
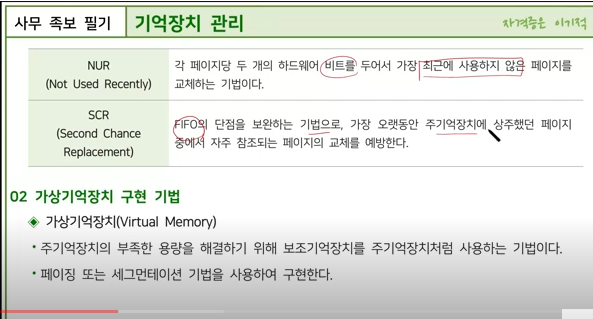
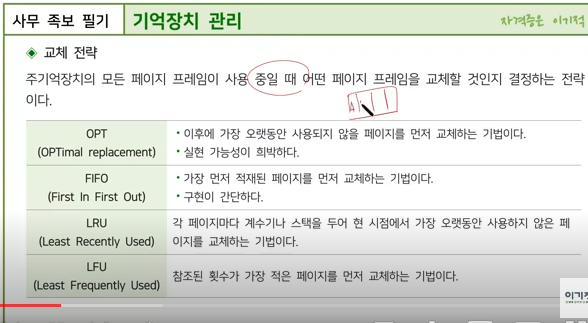
스래싱(Thrashing)은 컴퓨터 운영 체제에서 발생하는 현상으로, 시스템의 대부분의 시간을 페이지 폴트를 처리하는 데 사용하고 실제 유용한 작업에는 매우 적은 시간을 할애하는 상태를 말합니다. 12
스래싱이 발생하면, 프로세스는 메모리에 데이터나 코드를 로딩하려고 시도하지만, 메모리가 충분하지 않아 지속적으로 페이지 폴트가 발생하고, 이로 인해 데이터를 스왑 아웃하고 스왑 인하는 과정이 반복됩니다. 이러한 과정에서 시스템의 성능이 크게 저하되며, 심한 경우 시스템이 마비될 수도 있습니다. 1
스래싱 현상을 방지하기 위해서는 다중 프로그래밍의 정도를 낮추어야 하며, 각 프로세스들에게 충분한 페이지 프레임을 할당 할 수 있도록 해 주거나 주기억 장치 내에 워킹 세트(Working set)을 제대로 유지하는 것이 필요합니다. 또한 구역성(locality)을 이용해 페이지 교체 현상을 줄일 수 있습니다
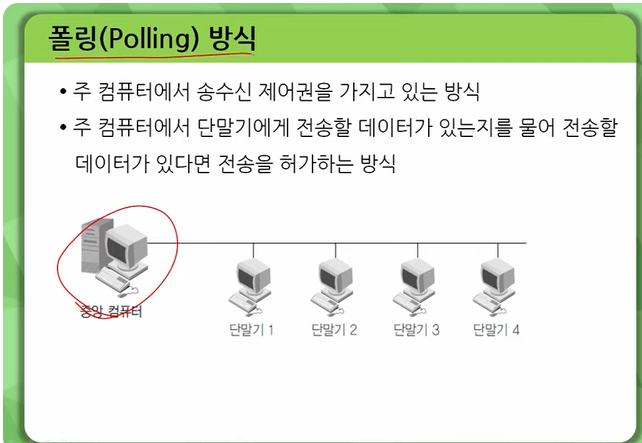
폴링(Polling) 방식은 주기적으로 시스템 콜을 호출하여 해당 이벤트가 발생했는지 여부를 확인하는 방식입니다. 이 방식은 이벤트가 발생했을 때 바로 반응할 수 있지만, 이벤트가 발생하지 않았을 때도 지속적으로 시스템 콜을 호출해야 하기 때문에 오버헤드가 크다는 단점이 있습니다. 또한 여러 개의 이벤트를 동시에 처리할 수 없습니다.
예를 들어, 서버에서 클라이언트로부터 데이터 전송 요청이 들어오면, 서버는 일정한 시간마다 클라이언트와의 소켓 연결 상태를 확인하여 데이터 전송이 완료되었는지 또는 오류가 발생했는지를 검사합니다. 이때 만약 데이터 전송이 아직 끝나지 않았다면 다시 대기상태로 들어가고, 데이터 전송이 완료되면 다음 동작을 진행합니다. 이러한 과정에서 반복되는 시스템 콜 호출로 인해 성능 저하가 발생할 수 있습니다.
따라서 일반적으로는 폴링 방식보다는 비동기 I/O 방식이나 이벤트 드리븐 방식을 더 많이 사용합니다. 그러나 일부 상황에서는 여전히 폴링 방식이 유용하게 사용되기도 합니다. 예를 들어, 특정 디바이스의 상태를 주기적으로 감시하거나 단순한 작업을 대량으로 처리할 때는 폴링 방식이 적합할 수 있습니다.
인터럽트는 컴퓨터 작동 중에 예기치 않은 문제가 발생한 경우에도 업무 처리가 계속될 수 있도록 하는 컴퓨터 운영 체계의 한 기능입니다. 1
프로세서(CPU, 중앙처리장치)의 즉각적인 처리를 필요로 하는 이벤트를 알리기 위해 발생하는 주변 하드웨어나 소프트웨어로부터의 요청을 말합니다. 인터럽트가 발생하면 그 순간 운영체계 내의 제어프로그램에 있는 인터럽트 처리 루틴이 작동하여 응급 사태를 해결하고 인터럽트가 생기기 이전의 상태로 복귀시킵니다. 1
인터럽트의 목적은 다음과 같습니다. 1
CPU 자원의 효율적 이용: 주변 장치의 속도가 CPU 속도보다 훨씬 느리기 때문에 주변 장치가 처리를 수행하는 동안 CPU는 다른 작업을 수행하고, 처리 종료 후 이를 알리기 위해 사용됩니다. 1
응답성 향상: 키보드, 마우스 등의 입력 장치에서 발생한 이벤트를 빠르게 처리하여 사용자의 요구에 신속하게 대응할 수 있습니다. 1
프로그래밍 방식에는 인터럽트 방식과 폴링(polling) 방식이 있는데, 정기적으로 CPU 상태를 확인하는 폴링 방법을 사용하게 되면 폴링을 위해 다른 처리의 효율이 떨어집니다. 따라서 인터럽트 방식을 사용할 경우 처리 종료 인터럽트를 받을 때까지 CPU는 다른 작업에 집중할 수 있습니다.
프로세스 제어 블록(Process Control Block, PCB)은 운영체제가 프로세스를 관리하기 위한 정보를 저장하는 자료구조입니다.
PCB에는 다음과 같은 정보가 포함됩니다.
프로세스 상태 정보: 실행 중인지 대기 중인지, 종료되었는지 등의 정보
CPU 레지스터 정보: 프로세스가 현재 실행 중인 CPU 레지스터 정보
프로그램 카운터 정보: 다음에 실행될 명령어의 주소
메모리 관리 정보: 프로세스가 할당받은 메모리 영역의 크기 및 위치 정보
입출력(I/O) 관련 정보: 프로세스가 요청한 I/O 작업의 상태 정보
부모 자식 관계 정보: 상위 프로세스와 하위 프로세스 간의 관계 정보
스케줄링 정보: 프로세스 우선순위, 실행 시간 등의 정보
PCB는 프로세스의 생명주기 동안 함께 이동하며, 프로세스의 상태 변화에 따라 해당 정보를 수정하고 관리합니다. 이를 통해 운영체제는 효율적으로 프로세스를 관리하고 처리할 수 있습니다
제어 프로그램의 종류와 특징은 다음과 같습니다. 1
TeamViewer
가장 유명한 PC 원격 제어 프로그램 중 하나입니다. 이 프로그램은 사용하기 쉽고 다양한 플랫폼에서 작동합니다. 또한, 파일 전송, 화면 공유, 화상 통화 등 다양한 기능을 제공하여 협업에 효과적으로 사용될 수 있습니다. 1
AnyDesk
TeamViewer와 유사한 기능을 제공하지만, 높은 속도와 낮은 대기 시간을 강조합니다. 이를 통해 더 빠르게 원격으로 컴퓨터를 조작할 수 있습니다. 또한, AnyDesk는 보안 기능을 강화하여 안전한 원격 접속을 제공합니다. 1
Chrome Remote Desktop
Google Chrome 브라우저를 통해 사용할 수 있는 원격 제어 프로그램입니다. 이 프로그램은 사용하기 간편하고 무료로 제공되며, 다양한 플랫폼에서 작동합니다. 또한, 안정성과 보안성을 강조하여 사용자들에게 안심하고 사용할 수 있는 환경을 제공합니다. 1
Remote Utilities
기업에서 원격지에 있는 여러 대의 컴퓨터를 관리할 수 있는 프로그램입니다. 이 프로그램은 다양한 기능을 제공하며, 사용자 인터페이스가 직관적이고 사용하기 쉽습니다. 1
AirDroid
모바일 기기에서 PC나 다른 모바일 기기를 원격으로 제어할 수 있는 앱입니다.
Microsoft Remote Desktop
마이크로소프트 윈도우 운영체제에서 사용할 수 있는 원격 제어 프로그램입니다.
LogMeIn
다양한 플랫폼에서 사용할 수 있는 원격 제어 프로그램으로, 기업에서도 많이 사용됩니다.
Splashtop
다양한 플랫폼에서 사용할 수 있는 원격 제어 프로그램으로, 빠른 속도와 안정성을 강조합니다.
Parsec
게임 스트리밍과 원격 제어를 동시에 할 수 있는 프로그램으로, 게임을 즐기는 사용자들에게 인기가 높습니다.
Virtual Network Computing(VNC): 다양한 플랫폼에서 사용할 수 있는 원격 제어 프로그램으로, 보안성이 뛰어나며 대규모 네트워크에서 사용하기 적합합니다.
조건문이란 조건식의 결과에 따라서 서로 다른 코드 블록을 실행시키는 문법입니다. 일반적으로 if-else 구문이나 switch-case 구문을 사용합니다.
if-else 구문은 조건식이 참인 경우 해당 코드 블록을 실행하고, 거짓인 경우 else 코드 블록을 실행합니다. 예를 들어, 다음과 같은 코드를 가정해보겠습니다.
python
Copy code
x = 10
y = 20
if x > y:
print("x가 더 큽니다.")
else:
print("y가 더 큽니다.")
위 코드는 변수 x와 y의 값을 비교하여 x가 더 큰 경우 "x가 더 큽니다."를 출력하고, 그렇지 않은 경우 "y가 더 큽니다."를 출력합니다.
switch-case 구문은 case 문 안에 주어진 값과 일치하는 경우 해당 코드 블록을 실행하고, 일치하지 않는 경우 default 코드 블록을 실행합니다. 예를 들어, 다음과 같은 코드를 가정해보겠습니다.
python
Copy code
x = 10
y = 20
구조화된 프로그래밍은 컴퓨터 프로그램의 구조를 여러 갈래로 분기하여, 복잡하게 하지 않고, 순서대로, 선택적으로 반복 문장을 사용하는 제어구조만을 사용한 프로그램입니다. 1
프로그램 개발 시 이해와 수정이 쉽고, 정확성을 검증하기 쉬워서 최종적으로 제어구조가 명확한 프로그램을 만들 수 있습니다. 구조적(構造的) 프로그래밍 또는 스트럭처드 프로그래밍이라고도 합니다. 1
컴퓨터의 프로그램을 만들 때 쉽게 이해할 수 있고, 수정하기 쉬우며, 정확성을 검증하기 쉬운 프로그램이 되도록 문제를 단계적으로 상세히 풀어나가서, 최종적으로는 제어구조(制御構造)가 명확한 프로그램을 만드는 방법론을 말합니다. 1
1960년대 말 E.W.다이크스트라가 주창한 프로그램 작성 기법입니다. 1
종전의 프로그램 작성 방법의 문제를 사전에 방지하기 위하여, 프로그램을 작성할 때에는 가급적 순서에 따라 차례로 하나씩 작성해 나가는 구조로 만들고, 처리 방법을 선택하는 문장을 사용하여 프로그램이 분기되지 않도록 하며, 반복 문장을 사용하는 것을 원칙으로 하고 있습니다. 1
이렇게 하면 프로그램을 실행할 때에 제어가 위에서 아래로 순차적으로 이루어지므로 이해하기 쉽고 수정하기도 쉬워지며, 오류를 찾기도 용이해집니다.
전위표현:
피연산자 앞에 연산자가 오는 표현 방법입니다.
예를 들어, "++a"는 a의 값을 1만큼 증가시킨 후 그 결과를 반환하는 전위 증가 연산자입니다.
중위표현:
일반적으로 가장 많이 사용되는 표현 방법으로, 연산자와 피연산자가 모두 등장하는 표현 방법입니다.
예를 들어, "a + b"는 a와 b를 더한 후 그 결과를 반환하는 중위 덧셈 연산자입니다.
후위표현:
피연산자 뒤에 연산자가 오는 표현 방법입니다.
예를 들어, "a++"는 a의 값을 반환한 후 a의 값을 1만큼 증가시키는 후위 증가 연산자입니다.
각 표현 방법은 장단점이 있으며, 상황에 따라 적절한 표현 방법을 선택해야 합니다. 예를 들어, 전위표현은 연산 속도가 빠르지만 메모리 사용량이 많을 수 있고, 후위표현은 메모리 사용량이 적지만 연산 속도가 느릴 수 있습니다.
따라서, 수식을 작성할 때는 목적과 상황에 따라 적절한 표현 방법을 선택하는 것이 중요합니다. 또한, 프로그래밍 언어마다 지원하는 표현 방법이 다를 수 있으므로, 사용하는 언어에 맞는 문법을 숙지해야 합니다.
다음은 수식 구문 표현에 대한 설명입니다.
괄호
괄호는 수식 내에서의 우선 순위를 결정하는데 사용되며, 일반적으로 안쪽에 있는 항목이 바깥쪽에 있는 항목보다 더 높은 우선 순위를 가집니다.
예를 들어, "2 + 3 * 4"라는 수식은 "2 + (3 * 4)"로 변경하면 올바른 결과를 얻을 수 있습니다. 이는 "+" 연산자가 "*" 연산자보다 낮은 우선 순위를 가지고 있기 때문입니다.
연산자
연산자는 두 개 이상의 피연산자를 결합하여 새로운 값을 생성하는 데 사용됩니다. 각 연산자는 특정한 우선 순위와 방향성을 가지며, 이를 이해하고 적절한 위치에 사용해야 합니다.
예를 들어, "2 + 3 - 4"라는 수식은 "((2 + 3) - 4)"로 변경하면 올바른 결과를 얻을 수 있습니다. 이는 "+" 연산자와 "-" 연산자가 동일한 우선 순위를 가지고 있으며 왼쪽에서 오른쪽으로 적용되기 때문입니다.
피연산자
피연산자는 연산자에 의해 조작되는 값 또는 데이터를 나타냅니다. 피연산자는 숫자, 문자, 문자열, 함수 호출 등 다양한 종류가 있을 수 있습니다.
예를 들어, "2 + 3"이라는 수식은 "2"와 "3" 두 개의 피연산자를 가지는 "+ 연산자"로 구성됩니다.
함수 호출
함수 호출은 함수를 호출하여 해당 함수의 반환 값을 얻는 동작을 나타냅니다. 함수 호출은 일종의 특수한 연산자로 간주되며, 그 자체로도 우선 순위와 방향성을 가질 수 있습니다.
예를 들어, "sqrt(16)"이라는 수식은 "sqrt" 함수를 호출하여 16의 제곱근을 구하는 동작을 나타냅니다.
복합 대입 연산자
복합 대입 연산자는 기존의 변수 값에 다른 값을 추가하거나 빼서 새로운 값을 생성하는 연산자입니다. 이들은 +=, -=, *=, /=, %= 등의 형태로 사용됩니다.
예를 들어, "x += y"라는 수식은 x의 값에 y의 값을 더해 새로운 값을 생성하고 다시 x에 저장하는 동작을 나타냅니다.
이러한 요소들을 잘 조합하여 복잡한 수식도 쉽게 이해하고 구현할 수 있습니다. 그러나 일부 경우에는 수식의 복잡성이 증가하면서 해석이 어려워질 수 있으므로 주의가 필요합니다. 또한, 수식의 정확성과 성능을 보장하기 위해서는 적절한 최적화 및 검증 절차가 필요합니다.
묵시적 순서 제어는 프로그램 실행 중 어떤 작업을 먼저 수행할지 명시적으로 지정하지 않아도 컴퓨터가 자동으로 판단하여 처리하는 방법을 말합니다. 대표적인 묵시적 순서 제어 방식으로는 다음과 같은 것들이 있습니다.
변수 할당
변수에 값을 할당하는 과정에서 우선순위가 높은 연산이 먼저 수행됩니다. 예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
python
Copy code
a = 10
b = 20
c = a + b
d = c * 100
e = d / 2
위 코드에서는 a, b, c, d, e 순으로 변수에 값을 할당합니다. 이때 c에 a+b를 할당한 후 d에 c*100을 할당한으므로 d값은 2000이 됩니다.
산술 연산
산술 연산에서도 우선순위가 높은 연산이 먼저 수행됩니다. 예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
python
Copy code
a = 10
b = 20
c = a + b
d = c * 100
e = d / 2
위 코드에서는 a+b를 계산한후 c에 저장하고 c*100을 계산한후 d에 저장합니다.
비교 연산
비교 연산에서도 우선순위가 높은 연산이 먼저 수행됩니다. 예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
python
Copy code
a = 10
b = 20
if (a > b) and (b < c):
print("a와 b는 서로 다른 값입니다.")
else:
print("a와 b는 같은 값입니다.")
위 코드에서는 (a>b)와 (b<c)를 동시에 만족해야 하므로 a와 b는 서로 다른 값이어야 합니다.
논리 연산
논리 연산에서도 우선순위가 높은 연산이 먼저 수행됩니다. 예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
python
Copy code
a = 10
b = 20
if (a > b) or (b < c):
print("a와 b는 서로 다른 값입니다.")
else:
print("a와 b는 같은 값입니다.")
위 코드에서는 (a>b)나 (b<c)중 하나만 만족해도 되므로 a와 b는 서로 다른 값이거나 같은 값이어도 됩니다.
묵시적 순서 제어는 프로그램을 작성할 때 편리하지만, 때로는 의도치 않은 결과를 초래할 수도 있습니다. 따라서 프로그램을 작성할 때는 항상 묵시적 순서 제어를 고려해야 하며, 가능하다면 명시적 순서 제어를 사용하는 것이 좋습니다.
또한, 프로그래밍 언어마다 묵시적 순서 제어의 규칙이 다르기 때문에, 사용하는 언어에 맞는 규칙을 숙지해야 합니다.
요약하자면, 묵시적 순서 제어는 프로그램 실행 중 어떤 작업을 먼저 수행할지 명시적으로 지정하지 않아도 컴퓨터가 자동으로 판단하여 처리하는 방법입니다. 대표적인 묵시적 순서 제어 방식으로는 변수 할당, 산술 연산, 비교 연산, 논리 연산 등이 있습니다. 프로그래밍 언어마다 묵시적 순서 제어의 규칙이 다르기 때문에, 사용하는 언어에 맞는 규칙을 숙지해야 합니다.
명시적 순서 제어란 프로그램 실행 중 어떤 작업을 먼저 수행할지 명시적으로 지정해주는 방법을 말합니다.
대표적인 명시적 순서 제어 방식으로는 다음과 같은 것들이 있습니다.
순차문
순차문은 조건 없이 정해진 순서대로 명령을 실행하는 문법입니다.
예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
python
Copy code
x = 0
y = 1
z = 2
# 순차문
for i in range(3):
print(i)
위 코드에서는 for 루프를 통해 0부터 2까지 반복하면서 i 변수를 출력합니다. 이때 i 값은 range() 함수에 의해 자동으로 증가하므로, 결과는 다음과 같습니다.
0
1
2
조건문
조건문은 주어진 조건에 따라 명령을 선택적으로 실행하는 문법입니다.
예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
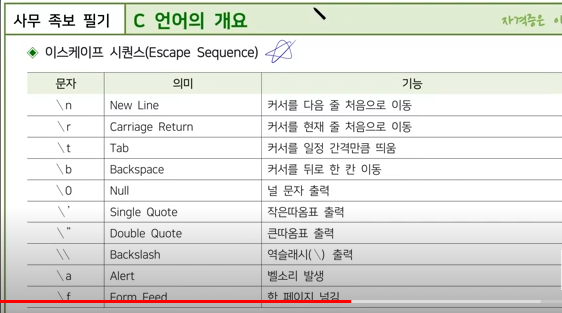
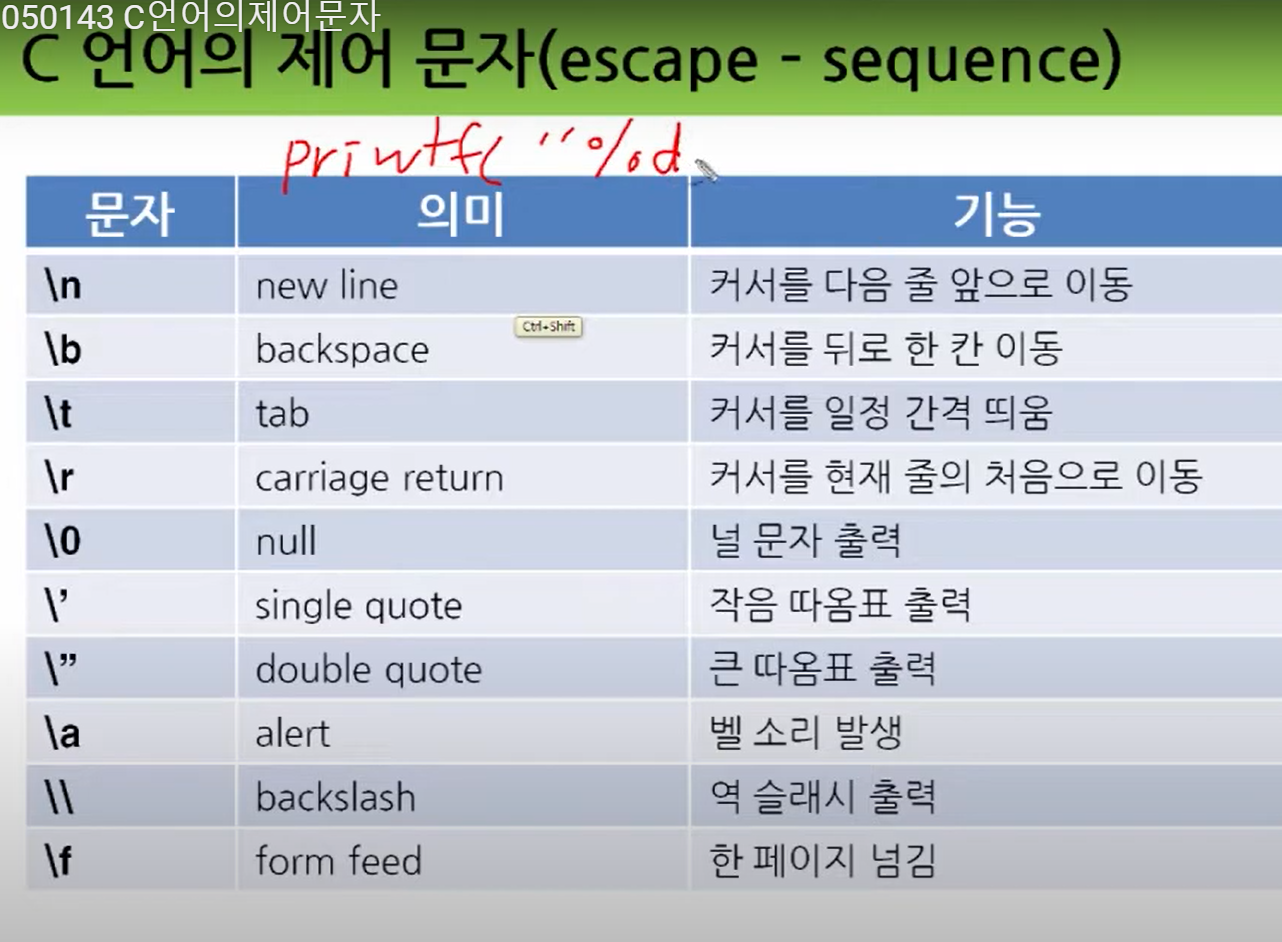
\n, \r, \f는 각각 줄바꿈, 캐리지리턴, 폼피드 문자라고 불리며, 텍스트 파일이나 문자열을 다룰 때 사용되는 특수 문자입니다.
줄바꿈
\n은 다음 행으로 이동하는 역할을 합니다. 예를 들어, "안녕하세요"라는 문장 뒤에 \n을 추가하면 다음 행으로 이동하여 출력됩니다.
python
Copy code
print("안녕하세요")
print("\n안녕하세요")
위 코드에서는 첫 번째 print 문에서는 "안녕하세요"라는 문장이 한 줄로 출력되고, 두 번째 print 문에서는 "안녕하세요"라는 문장이 다음 행으로 이동하여 출력됩니다.
캐리지리턴
\r은 현재 위치에서 커서를 맨 앞으로 이동시키는 역할을 합니다. 예를 들어, "안녕하세요"라는 문장 뒤에 \r을 추가하면 기존에 있던 "안녕하세요"라는 문장이 지워지고 그 자리에 다시 "안녕하세요"라는 문장이 출력됩니다.
python
Copy code
print("안녕하세요")
print("\r안녕하세요")
위 코드에서는 첫 번째 print 문에서는 "안녕하세요"라는 문장이 한 줄로 출력되고, 두 번째 print 문에서는 기존에 있던 "안녕하세요"라는 문장이 지워지고 그 자리에 다시 "안녕하세요"라는 문장이 출력됩니다.
폼피드
\f는 페이지를 강제로 넘기는 역할을 합니다. 예를 들어, "안녕하세요"라는 문장 뒤에 \f를 추가하면 해당 페이지가 강제로 넘어가게 됩니다. 하지만 일반적으로 웹 브라우저에서는 이 기능이 지원되지 않기 때문에 대부분의 경우에는 사용되지 않습니다.
이러한 특수 문자들은 주로 텍스트 파일이나 문자열을 다루거나, 프로그래밍 언어에서 데이터를 처리할 때 사용됩니다. 그러나 이러한 특수 문자들을 직접 입력하는 것은 어렵기 때문에, 보통은 escape sequence를 사용하여 표현합니다. 예를 들어, \n은 \n으로, \r은 \r으로, \f는 \f로 표현할 수 있습니다.
escape sequence는 각 프로그래밍 언어마다 조금씩 다를 수 있으므로, 사용하는 언어에 맞게 적절한 escape sequence를 사용해야 합니다.
요약하자면, \n, \r, \f는 각각 줄바꿈, 캐리지리턴, 폼피드 문자로서 텍스트 파일이나 문자열을 다룰 때 사용되는 특수 문자입니다. 이들은 escape sequence를 사용하여 표현할 수 있으며, 각 프로그래밍 언어마다 약간씩 차이가 있을 수 있습니다.
구조체(struct)는 여러 개의 변수를 묶어서 새로운 자료형을 만드는 데 사용됩니다. 이는 마치 레고 블록처럼 여러 개의 작은 부품을 조합해서 큰 물체를 만드는 것과 유사합니다.
구조체는 다음과 같은 형식으로 정의됩니다. 12
struct 구조체이름 { [1][1][2][2]
변수1 자료형;
변수2 자료형;
...
변수n 자료형;
};
여기서 구조체이름은 새로 만들어지는 자료형의 이름이며, 변수1, 변수2, ..., 변수n은 해당 자료형의 구성원(멤버)입니다. 각 멤버는 각자의 자료형을 가지며, 이 자료형은 미리 정의된 기본 자료형(int, float, double, char 등)이거나 사용자가 직접 만든 구조체일 수도 있습니다. 2
구조체를 이용하면 다음과 같은 이점을 얻을 수 있습니다.
데이터의 그룹화
여러 개의 변수를 하나의 자료형으로 묶으면 데이터를 더욱 쉽게 관리할 수 있습니다.
데이터의 공유
구조체로 만들어진 자료형은 다른 함수나 모듈에서도 사용할 수 있습니다. 이를 통해 데이터의 재활용성을 높일 수 있습니다.
데이터의 보안성
구조체 내부에 있는 멤버들은 외부로부터 접근이 제한될 수 있습니다. 이를 통해 데이터의 보안성을 강화할 수 있습니다.
구조체는 주로 다음과 같은 용도로 사용됩니다.
데이터의 그룹화
여러 개의 변수를 하나의 자료형으로 묶어서 데이터를 관리합니다.
데이터의 공유
구조체로 만들어진 자료형은 다른 함수나 모듈에서도 사용할 수 있습니다. 이를 통해 데이터의 재활용성을 높입니다.
데이터의 보안성
구조체 내부에 있는 멤버들은 외부로부터 접근이 제한될 수 있습니다. 이를 통해 데이터의 보안성을 강화합니다.
예를 들어, 다음과 같은 구조체를 만들어보겠습니다.
struct Person {
string name;
int age;
string email;
};
이는 Person이라는 이름의 구조체로서, name, age, email 세 개의 멤버를 가지고 있습니다. 각 멤버는 string과 int라는 자료형을 가지고 있습니다.
이 구조체를 이용해 다음과 같은 코드를 작성할 수 있습니다.
#include <iostream>
#include <string>
using namespace std;
struct Person {
string name;
int age;
string email;
};
int main() {
Person person1;
person1.name = "홍길동";
person1.age = 30;
person1.email = "hong@naver.com";
Person person2;
person2.name = "김유신";
person2.age = 25;
person2.email = "yushin@gmail.com";
cout << "person1의 이름은 " << person1.name << "입니다." << endl;
cout << "person1의 나이는 " << person1.age << "세입니다." << endl;
cout << "person1의 이메일 주소는 " << person1.email << "입니다." << endl;
cout << "person2의 이름은 " << person2.name << "입니다." << endl;
cout << "person2의 나이는 " << person2.age << "세입니다." << endl;
cout << "person2의 이메일 주소는 " << person2.email << "입니다." << endl;
return 0;
}
이 코드는 Person 구조체를 이용해 두 명의 인물 정보를 저장하고 출력하는 예시입니다. person1과 person2 두 개의 변수를 만들어서 각각의 인물 정보를 저장하고, cout 함수를 이용해 각 멤버의 값을 출력합니다.
이렇게 구조체를 이용하면 여러 개의 변수를 하나의 자료형으로 묶어서 보다 편리하게 데이터를 관리할 수 있습니다.
마크다운에서는 배열을 지원하지 않기 때문에 일반 텍스트로 설명 드리겠습니다.
프로그래밍에서 배열(Array)은 동일한 자료형을 가지는 값들을 연속적인 메모리 공간에 저장한 자료구조입니다. 각 요소들은 인덱스로 접근할 수 있으며, 인덱스는 0부터 시작합니다. 예를 들어, 정수값을 저장하는 배열 my_array가 있다면, my_array[0], my_array[1], my_array[2]와 같이 각 요소에 접근할 수 있습니다.
C/C++나 파이썬 등 대부분의 프로그래밍 언어에서 배열을 지원하며, 각각의 언어마다 구현 방식이나 문법이 다를 수 있습니다. 또한, 배열은 크기가 고정되어 있기 때문에 추가 또는 삭제가 불가능한 경우도 있지만, 동적으로 크기를 조절할 수 있는 동적 배열(Dynamic Array)이라는 개념도 있습니다.
사용 방법은 해당 언어의 문법에 따라 다르지만, 대체로 다음과 같은 단계로 이루어집니다.
배열 선언: 자료형[] 배열명; 또는 자료형 배열명[];
초기화: 배열명 = new 자료형[크기]; 또는 배열명 = [값, 값, ...];
요소 접근: 배열명[인덱스] = 값; 또는 값 = 배열명[인덱스];
종료: delete [] 배열명; 또는 del 배열명[:];
예를 들어, C++에서 정수값을 저장하는 배열을 선언하고 초기화하는 예제는 다음과 같습니다.
c
Copy code
int my_array []; // 배열 선언
my_array = new int[10]; // 크기 10으로 초기화
for (int i=0; i<10; i++) {
my_array[i] = i; // 각 요소에 값 할당
}
for (int i=0; i<10; i++) {
cout << my_array[i] << endl; // 각 요소 출력
}
delete [] my_array; // 배열 해제
위 예제에서 my_array는 크기가 10인 정수값을 저장하는 배열입니다. new int[10] 명령어로 초기화하고, for 루프를 사용하여 각 요소에 값을 할당하고 출력합니다. 마지막으로 delete [] my_array 명령어로 배열을 해제합니다.
각 언어마다 문법이 조금씩 다르기 때문에 자세한 내용은 해당 언어의 공식 문서를 참고하시면 됩니다.
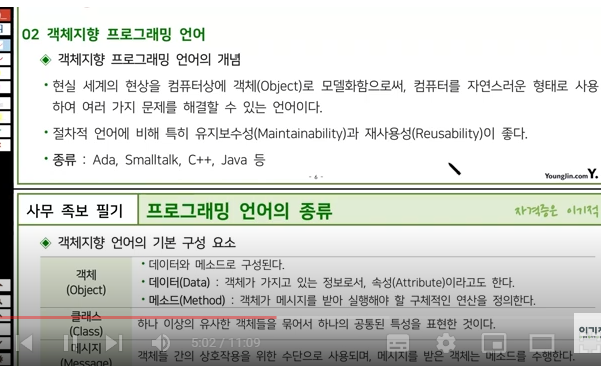
객체 지향 프로그래밍(OOP)은 소프트웨어 공학에서 사용되는 개념으로, 컴퓨터 프로그램을 객체들의 집합으로 구성하고 이들 간의 상호작용을 통해 원하는 작업을 수행하도록 하는 기법입니다. OOP는 코드 재사용 및 관리 용이성, 상속성, 추상화, 다형성 등의 장점을 가지고 있으며 대표적인 객체 지향 언어로는 Java, Python, C++, Ruby 등이 있습니다.
다음은 객체 지향 언어의 주요 특징입니다.
캡슐화
관련 있는 변수와 메서드를 하나의 클래스 안에 묶는 것을 말합니다. 캡슐화를 통해 데이터를 보호하고 일관성 있게 관리할 수 있습니다.
상속
상위 클래스의 멤버들을 하위 클래스가 물려받는 것을 말합니다. 상속을 통해 코드 중복을 줄이고 효율적인 코드 작성이 가능합니다.
추상화
불필요한 세부 사항을 감추고 필요한 기능만 노출시키는 것을 말합니다. 추상화를 통해 복잡한 문제를 단순화하고 이해하기 쉬운 모델을 만들 수 있습니다.
다형성
한 클래스의 인스턴스가 여러 종류의 타입을 가질 수 있는 것을 말합니다. 다형성을 통해 다양한 상황에 유연하게 대처할 수 있습니다.
클래스 간의 관계
두 개 이상의 클래스 사이에는 서로 관계가 존재하는데, 이러한 관계를 정의하는 것을 말합니다. 클래스 간의 관계에는 상속관계, 포함관계, 협력관계 등이 있습니다.
참고정보
캡슐화는 객체지향프로그래밍에서의 중요한 특징 중 하나로, 연관된 데이터와 함수를 논리적으로 묶어놓은 것이며, 데이터를 보호하기 위해 다른 객체의 접근을 제한하는 접근 제한 수식자의 기능을 제공합니다. 1
객체의 속성(data fields)과 행위(methods)를 하나로 묶고, 실제 구현 내용 일부를 외부에 감추어 은닉함으로써 응집도가 올라가므로 자율적인 객체가 되며, 자신의 상태를 스스로 처리할 수 있습니다. 이때, 은닉화가 이루어지지 않는다면 객체는 스스로의 상태를 처리하지 못하고, 외부에서 속성을 꺼내와서 상태를 수정하게 되어 높은 결합도와 낮은 응집도를 지닌 수동적인 객체가 됩니다. 이렇게 수동적인 객체는 프로그램의 유지 보수를 어렵게 하므로 은닉화를 통해 데이터의 손상과 오류 발생을 최소화시키고, 객체 조작 방법이나 데이터가 변경되어도 사용방법은 변경되지 않아 다른 객체에 영향을 끼치지 않습니다. 이를 통해 독립성이 유지되며 객체간의 결합도가 낮아져 인터페이스가 간단해집니다. 사용자는 데이터가 처리된 결과만을 사용하기 때문에 객체의 이식성이 뛰어납니다. 일반적인 객체지향프로그래밍에서는 public, protected, private와 같은 접근지정자를 제공하며, 자바스크립트에서도 캡슐화를 지원합니다.
객체 클래스란 객체 지향 프로그래밍(OOP)에서 데이터와 그 데이터를 조작하는 함수들을 하나로 묶어 놓은 것을 말합니다.
객체 클래스는 다음과 같은 요소들로 구성됩니다.
필드
객체의 상태를 나타내는 변수입니다. 필드는 private 또는 public 접근 권한을 가질 수 있으며, private 필드는 외부에서 직접 접근할 수 없고, public 필드는 외부에서 직접 접근할 수 있습니다.
메서드
객체의 동작을 나타내는 함수입니다. 메서드는 반환값이 있을 수도 있고 없을 수도 있습니다. 또한, 메서드도 private 또는 public 접근 권한을 가질 수 있으며, private 메서드는 외부에서 직접 호출할 수 없습니다.
객체 클래스는 new 연산자를 사용하여 객체를 생성할 수 있으며, 생성된 객체는 자신의 필드와 메서드를 통해 데이터를 저장하고 조작할 수 있습니다. 예를 들어, 다음과 같은 Person 클래스가 있다고 가정해봅시다.
python
Copy code
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def get_name(self):
return self.name
def set_name(self, name):
self.name = name
def get_age(self):
return self.age
def set_age(self, age):
if not isinstance(age, int):
raise ValueError("Age must be an integer")
self.age = age
person1 = Person("John", 30)
print(person1.get_name()) # John
print(person1.get_age()) # 30
person1.set_name("Alice")
print(person1.get_name()) # Alice
try:
person1.set_age("30")
except ValueError as e:
print(e) # Age must be an integer
위 코드에서는 Person 클래스의 생성자 __init__() 메서드를 사용하여 이름과 나이를 초기화하고, get_name(), set_name(), get_age(), set_age() 메서드를 사용하여 이름과 나이를 조회하거나 수정할 수 있습니다. 이렇게 생성된 객체는 독립적으로 존재하며, 다른 객체와는 서로 영향을 미치지 않습니다. 이러한 특징을 캡슐화라고 합니다.
또한, 위 코드에서는 set_age() 메서드에서 입력받은 값이 정수인지 검사하여 그렇지 않은 경우에는 예외를 발생시키는 예제를 보여주고 있습니다. 이처럼 객체 클래스에서는 오류 처리나 보안 문제 등을 고려하여 메서드를 설계해야 합니다.
이스케이프 시퀀스(Escape Sequence)는 프로그래밍 언어에서 특별한 의미를 갖는 문자 조합으로, 일반적인 문자와는 다른 의미를 갖습니다. 주로 문자열을 다룰 때 사용되며, 다음은 여러 가지 이스케이프 시퀀스 중 자주 사용되는 몇 가지 예시입니다. 12
\n
개행을 의미합니다.
\t
탭을 의미합니다. 1
\'
작은 따옴표를 의미합니다. 1
\"
큰 따옴표를 의미합니다. 1
\
백슬래시를 의미합니다.
예를 들어, 다음과 같이 문자열을 정의할 때 이스케이프 시퀀스를 사용할 수 있습니다. 12
python
Copy code
string1 = "Hello i'm a person"
string2 = "Hello i'm a person"
print(len(string1)) # 15
print(len(string2)) # 13
위 코드에서 string1은 이스케이프 시퀀스를 사용하여 작은 따옴표를 포함한 문자열을 정의한 반면, string2는 이스케이프 시퀀스를 사용하지 않았습니다. 따라서 string1의 길이는 15이고, string2의 길이는 13입니다. 이처럼 이스케이프 시퀀스는 문자열을 다루는데 매우 유용하게 사용됩니다
입출력함수의 변환문자
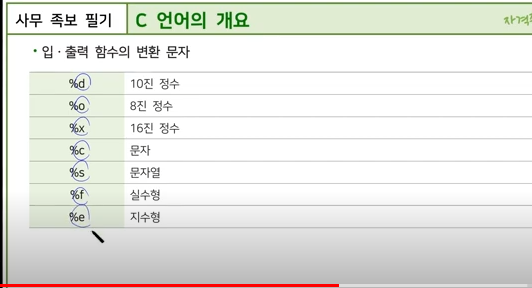
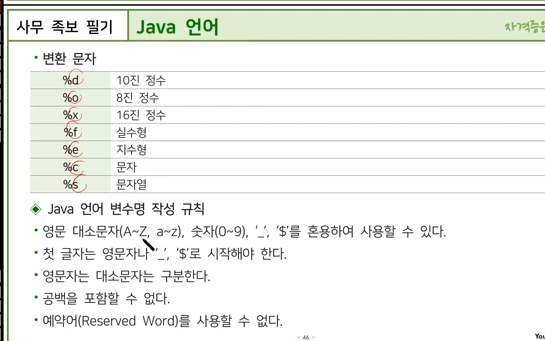
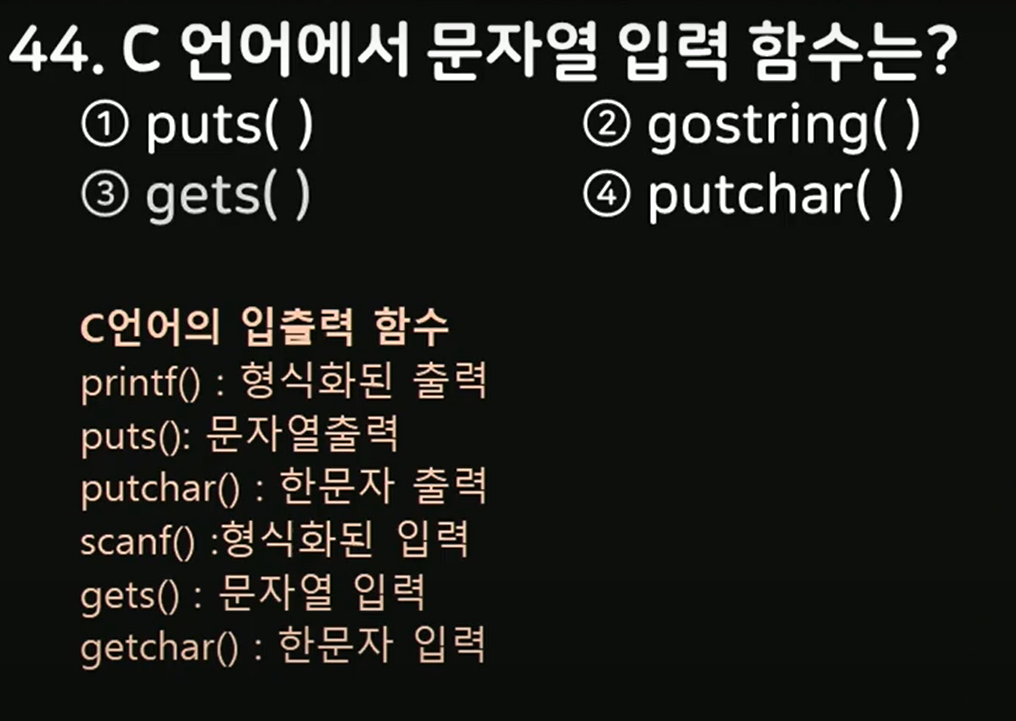
C 언어에서 입출력 함수를 사용할 때, 다양한 데이터 타입을 출력하거나 입력받기 위해 변환 문자를 사용합니다. 변환 문자는 printf와 scanf 함수에서 각 데이터 타입을 지정하여 올바르게 처리할 수 있도록 합니다. 주요 변환 문자와 그 용도를 정리해보겠습니다.
printf 함수의 변환 문자
printf 함수는 데이터를 형식에 맞춰 출력하는 함수입니다. 각 변환 문자는 출력할 데이터 타입을 나타냅니다.
%d, %i: 정수형(int)
c
코드 복사
int num = 10;
printf("%d\n", num); // 출력: 10
%u: 부호 없는 정수형(unsigned int)
c
코드 복사
unsigned int num = 10;
printf("%u\n", num); // 출력: 10
%f: 부동 소수점형(float)
c
코드 복사
float num = 3.14;
printf("%f\n", num); // 출력: 3.140000
%lf: 이중 정밀도 부동 소수점형(double)
c
코드 복사
double num = 3.141592653589793;
printf("%lf\n", num); // 출력: 3.141593
%c: 문자형(char)
c
코드 복사
char letter = 'A';
printf("%c\n", letter); // 출력: A
%s: 문자열(char 배열)
c
코드 복사
char str[] = "Hello";
printf("%s\n", str); // 출력: Hello
%x, %X: 16진수 정수형 (int)
c
코드 복사
int num = 255;
printf("%x\n", num); // 출력: ff
printf("%X\n", num); // 출력: FF
%o: 8진수 정수형 (int)
c
코드 복사
int num = 255;
printf("%o\n", num); // 출력: 377
%%: 퍼센트 기호
c
코드 복사
printf("100%%\n"); // 출력: 100%
scanf 함수의 변환 문자
scanf 함수는 데이터를 형식에 맞춰 입력받는 함수입니다. 각 변환 문자는 입력할 데이터 타입을 나타냅니다.
%d, %i: 정수형(int)
c
코드 복사
int num;
scanf("%d", &num);
%u: 부호 없는 정수형(unsigned int)
c
코드 복사
unsigned int num;
scanf("%u", &num);
%f: 부동 소수점형(float)
c
코드 복사
float num;
scanf("%f", &num);
%lf: 이중 정밀도 부동 소수점형(double)
c
코드 복사
double num;
scanf("%lf", &num);
%c: 문자형(char)
c
코드 복사
char letter;
scanf(" %c", &letter); // 앞의 공백은 이전 입력의 공백 문자를 무시하기 위함
%s: 문자열(char 배열)
c
코드 복사
char str[100];
scanf("%s", str);
%x: 16진수 정수형 (int)
c
코드 복사
int num;
scanf("%x", &num);
%o: 8진수 정수형 (int)
c
코드 복사
int num;
scanf("%o", &num);
예제 코드
아래 예제 코드는 printf와 scanf 함수를 사용하여 다양한 데이터 타입을 입력받고 출력하는 예제입니다:
c
코드 복사
#include <stdio.h>
int main() {
int a;
unsigned int b;
float c;
double d;
char e;
char str[100];
printf("정수를 입력하세요: ");
scanf("%d", &a);
printf("입력된 정수: %d\n", a);
printf("부호 없는 정수를 입력하세요: ");
scanf("%u", &b);
printf("입력된 부호 없는 정수: %u\n", b);
printf("실수를 입력하세요: ");
scanf("%f", &c);
printf("입력된 실수: %f\n", c);
printf("이중 정밀도 실수를 입력하세요: ");
scanf("%lf", &d);
printf("입력된 이중 정밀도 실수: %lf\n", d);
printf("문자를 입력하세요: ");
scanf(" %c", &e); // 공백 문자를 무시하기 위해 앞에 공백 추가
printf("입력된 문자: %c\n", e);
printf("문자열을 입력하세요: ");
scanf("%s", str);
printf("입력된 문자열: %s\n", str);
return 0;
}
이 코드는 다양한 데이터 타입을 입력받고, 해당 데이터를 출력하는 방식으로 변환 문자를 활용하는 예를 보여줍니다.
C언어에서의 반복 처리문은 프로그램 실행 중 일정한 횟수나 조건이 만족될 때까지 반복해서 명령을 실행하는 데 사용됩니다. 대표적인 반복 처리문으로는 다음과 같은 것들이 있습니다.
for 문
초기값, 조건식, 증감식을 통해 반복 횟수를 명확히 알 수 있는 경우에 사용합니다.
c
Copy code
#include <stdio.h>
int main() {
for (int i = 0; i < 5; i++) {
puts("Hello World!");
}
return 0;
}
위 예제에서는 i 변수를 0부터 4까지 총 5번 반복하며, 매 반복마다 "Hello World!"를 출력합니다.
while 문
조건식이 참인 동안 계속해서 명령을 실행합니다.
c
Copy code
#include <stdio.h>
int main() {
int i = 0;
while (i < 5) {
puts("Hello World!");
i++;
}
return 0;
}
위 예제에서는 i 변수가 5보다 작은 동안 계속해서 "Hello World!"를 출력하고, 이후에는 종료됩니다.
do∼while 문
조건식이 참이든 거짓이든 한 번은 명령을 실행하고, 이후에는 조건식이 참인 동안 계속해서 명령을 실행합니다.
c
Copy code
#include <stdio.h>
int main() {
int i = 0;
do {
puts("Hello World!");
i++;
} while (i < 5);
return 0;
}
위 예제에서는 i 변수가 5보다 작으면 무조건 한 번은 "Hello World!"를 출력하고, 이후에는 i 변수가 5보다 커질 때까지 계속해서 "Hello World!"를 출력합니다.
이러한 반복 처리문은 C언어에서 매우 자주 사용되므로 반드시 숙지해야 합니다. 특히, for 문과 while 문은 가장 많이 사용되는 반복 처리문 중 하나입니다.
C언어에서 기타 제어문으로는 다음과 같은 것들이 있습니다.
if-else 문
조건에 따라 서로 다른 명령을 실행할 때 사용합니다. 예를 들어, 만약 어떤 값이 10보다 크다면 A라는 명령을 실행하고, 그렇지 않으면 B라는 명령을 실행하는 식입니다.
c
Copy code
#include <stdio.h>
int main() {
int x = 20;
if (x > 10) {
puts("x는 10보다 큽니다.");
} else {
puts("x는 10보다 크지 않습니다.");
}
return 0;
}
switch 문
여러 가지 조건 중 하나를 선택하여 해당 명령을 실행할 때 사용합니다. 예를 들어, 만약 어떤 값이 1이면 A라는 명령을 실행하고, 2이면 B라는 명령을 실행하는 식입니다.
c
Copy code
#include <stdio.h>
C언어에서의 제어문은 프로그램 실행 중 특정 조건에 따라 실행 경로를 선택하거나 반복 작업을 처리하는데 사용됩니다. 대표적인 제어문으로는 다음과 같은 것들이 있습니다.
if 문
주어진 조건식이 참인 경우에만 지정된 블록의 코드를 실행합니다.
c
Copy code
#include <stdio.h>
int main() {
int x = 10;
if (x == 10) {
puts("x는 10입니다.");
} else {
puts("x는 10이 아닙니다.");
}
return 0;
}
위 예제에서는 x 변수의 값이 10인지 여부에 따라 두 가지 실행 경로 중 하나를 선택합니다. 만약 x가 10이면 "x는 10입니다."라는 문자열이 출력되고, 그렇지 않으면 "x는 10이 아닙니다."라는 문자열이 출력됩니다.
else if 문
여러 개의 조건을 검사하여 그 중 하나라도 참인 경우 해당 블록의 코드를 실행합니다.
c
Copy code
#include <stdio.h>
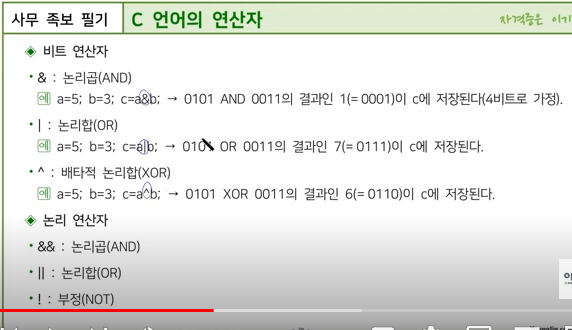
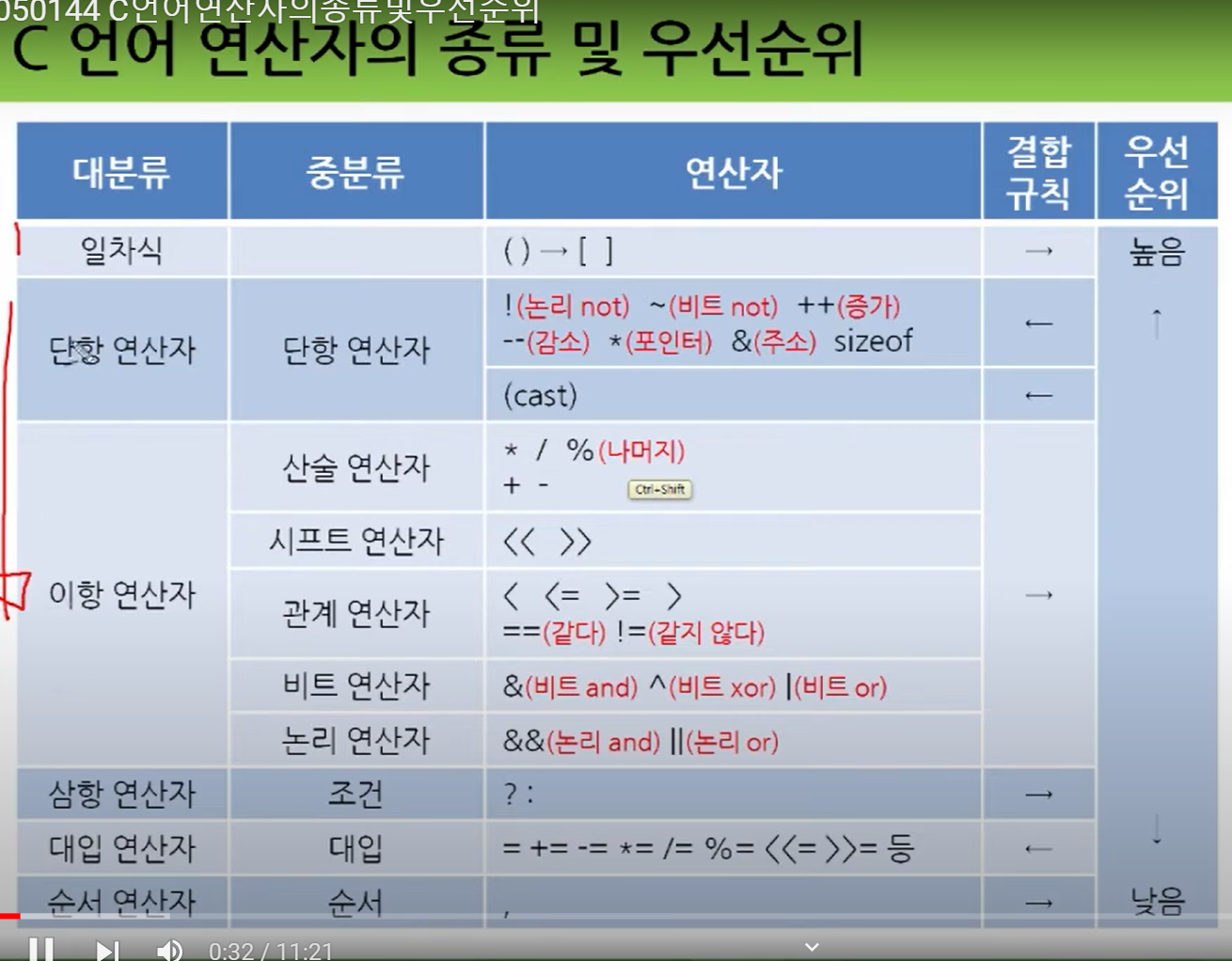
C언어의 논리 연산자와 할당 연산자는 다음과 같습니다. 12
논리 연산자: &&, ||, !
할당 연산자: =, +=, -=, *=, /=, %=, &=, |=, ^=, <<=, >>=
논리 연산자는 조건식을 평가할 때 사용되며, 할당 연산자는 변수의 값을 변경할 때 사용됩니다.
예를 들어, 다음 코드는 논리 연산자와 할당 연산자를 이용하여 변수의 값을 계산하는 예시입니다.
c
Copy code
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
// 논리 연산자
if (a > b && b > 10) {
printf("a와 b 모두 10보다 큽니다.\n");
} else if (a < b || b < 10) {
printf("a와 b 중 하나 이상이 10보다 작습니다.\n");
} else {
printf("a와 b 모두 10과 같습니다.\n");
}
// 할당 연산자
a += b;
b -= a;
printf("a = %d, b = %d\n", a, b);
return 0;
}
위 코드에서 논리 연산자들은 &&, ||, !이며, 각각 AND, OR, NOT 연산을 수행합니다. 또한, 할당 연산자들은 +=, -=, *=, /=, %=, &=, |=, ^=, <<=, >>=로, 변수의 값을 변경하면서 해당 연산을 수행합니다. 1
이러한 논리 연산자와 할당 연산자는 C언어에서 매우 자주 사용되는 연산자이므로 반드시 숙지해야 합니다.
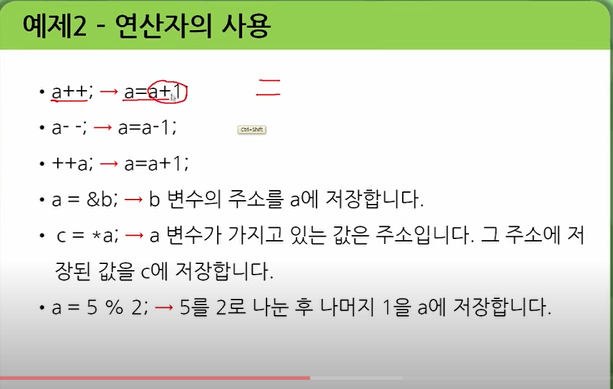
산술 연산자와 증가/감소 연산자는 C언어에서 매우 중요한 역할을 합니다.
산술 연산자: +,-,*,/,%,,++,-- 1
증가/감소 연산자: ++,--
산술 연산자는 두 개의 피연산자를 이용하여 사칙연산, 나머지 연산 등을 수행합니다. 1
증가/감소 연산자는 변수의 값을 1씩 증가시키거나 감소시키는 연산을 수행합니다.
예를 들어, 다음 코드는 산술 연산자와 증가/감소 연산자를 이용하여 변수의 값을 계산하는 예시입니다.
c
Copy code
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
// 산술 연산자
printf("a + b = %d\n", a + b); // 30
printf("a - b = %d\n", a - b); // -10
printf("a * b = %d\n", a * b); // 200
printf("a / b = %f\n", (float)a / b); // 0.5
printf("a % b = %d\n", a % b); // 10
// 증가/감소 연산자
printf("\na = %d\n", a++); // 10
printf("a = %d\n", a); // 11
printf("\nb = %d\n", --b); // 19
printf("b = %d\n", b); // 18
return 0;
}
위 코드에서 산술 연산자들은 +, -, *, /, %이며, 각각 덧셈, 뺄셈, 곱셈, 나눗셈, 나머지 연산을 수행합니다. 또한, 증가/감소 연산자들은 ++와 --로, 변수의 값을 1씩 증가시키거나 감소시킵니다. 1
이러한 산술 연산자와 증가/감소 연산자는 C언어에서 매우 자주 사용되는 연산자이므로 반드시 숙지해야 합니다.
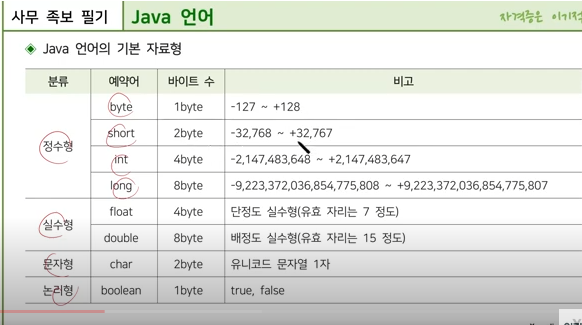
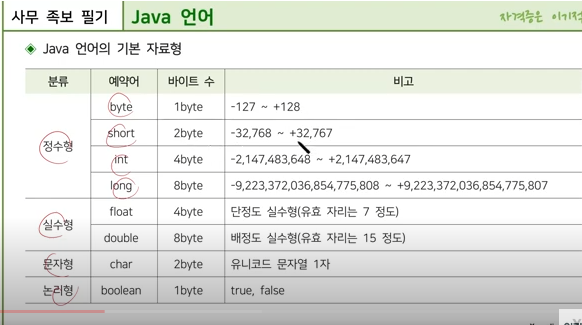
C언어의 기본 자료형은 다음과 같습니다.
정수형
signed char, unsigned char, short, unsinged short, int, unsigned int, long, unsigned long 등이 있습니다.
실수형
float, double, long double 등이 있습니다.
문자형
char 형이 있습니다.
부동소수점형
float, double, long double 등이 있습니다.
논리형
bool 형이 있습니다.
c언어의 5가지 기본 자료형
C 언어에는 데이터를 저장하고 처리하기 위해 여러 가지 기본 자료형이 제공됩니다. 이 기본 자료형들은 다양한 종류의 데이터를 표현하기 위해 사용되며, 각각의 자료형은 특정 범위와 크기를 가지고 있습니다. C 언어의 5가지 기본 자료형은 다음과 같습니다:
1. int (정수형)
정수형은 정수를 저장하는 데 사용됩니다. 정수형 변수는 양수, 음수 및 0을 저장할 수 있습니다.
크기: 일반적으로 4바이트(32비트)이나, 시스템에 따라 다를 수 있습니다.
범위: 시스템에 따라 다르지만, 일반적으로 -2,147,483,648에서 2,147,483,647까지의 값을 가집니다.
c
코드 복사
int a = 10;
int b = -5;
2. float (부동 소수점형)
부동 소수점형은 소수점을 포함한 실수를 저장하는 데 사용됩니다. 주로 과학적 계산이나 소수점 이하의 정밀도가 필요한 경우 사용됩니다.
크기: 일반적으로 4바이트(32비트).
범위 및 정밀도: 1.2E-38에서 3.4E+38까지의 범위와 약 6자리의 십진수 정밀도를 가집니다.
c
코드 복사
float pi = 3.14f;
float e = 2.718f;
3. double (이중 정밀도 부동 소수점형)
이중 정밀도 부동 소수점형은 더 높은 정밀도의 실수를 저장하는 데 사용됩니다. float보다 더 넓은 범위와 높은 정밀도를 제공합니다.
크기: 일반적으로 8바이트(64비트).
범위 및 정밀도: 2.3E-308에서 1.7E+308까지의 범위와 약 15자리의 십진수 정밀도를 가집니다.
c
코드 복사
double pi = 3.141592653589793;
double largeNumber = 1.23e100;
4. char (문자형)
문자형은 단일 문자를 저장하는 데 사용됩니다. 주로 ASCII 코드를 사용하여 문자 데이터를 표현합니다.
크기: 일반적으로 1바이트(8비트).
범위: 0에서 255까지의 값을 가지며, 보통 -128에서 127 또는 0에서 255의 범위를 가집니다.
c
코드 복사
char letter = 'A';
char digit = '5';
5. void (무형)
void 자료형은 값이 없음을 나타내기 위해 사용됩니다. 주로 함수의 반환형이나 포인터의 타입을 명시할 때 사용됩니다.
크기: 크기가 없으며, 데이터 저장용이 아님.
용도: 반환 값이 없는 함수, 제네릭 포인터 등을 나타냅니다.
c
코드 복사
void printHello() {
printf("Hello, World!");
}
예제 코드
아래는 위의 기본 자료형들을 사용하는 간단한 C 프로그램 예제입니다:
c
코드 복사
#include <stdio.h>
int main() {
// int 형 변수
int age = 25;
printf("Age: %d\n", age);
// float 형 변수
float height = 175.5;
printf("Height: %.2f cm\n", height);
// double 형 변수
double pi = 3.141592653589793;
printf("Pi: %.15f\n", pi);
// char 형 변수
char initial = 'J';
printf("Initial: %c\n", initial);
// void 형 함수 호출
printHello();
return 0;
}
void printHello() {
printf("Hello, World!\n");
}
이 예제는 C 언어의 기본 자료형을 사용하여 다양한 데이터 타입을 저장하고 출력하는 방법을 보여줍니다.
포인터(pointer)는 다른 변수의 주소를 값으로 갖는 변수입니다. 모든 변수는 비어있는 어딘가의 메모리 공간에 저장되는데 메모리의 각 바이트에는 주소가 매겨져 있습니다. 이러한 주소를 포인터 변수에 저장할 수 있습니다. 1
위 그림에서 P는 변수 A를 가리키는 포인터 변수입니다. 예를 하나 자면 위 코드에서 num이라는 변수가 int형으로 선언되었습니다. 그리고 Pnum은 num 변수의 주소를 저장하는 포인터 변수입니다.
포인터는 C언어에서 가장 어렵게 느껴지는 부분이면서도 C언어의 가장 큰 특징이기도 합니다. 그러나 포인터는 프로그램을 효율적으로 할 수 있게 해주는 녀석인 만큼 잘 숙지하고 있어야 합니다.
프로그래밍에서 변수와 상수는 데이터를 저장하고 관리하는 중요한 요소입니다. 두 개념은 데이터 값을 저장한다는 점에서는 유사하지만, 사용하는 방식과 성질에서 차이가 있습니다.
변수 (Variable)
변수는 프로그램에서 데이터 값을 저장하기 위해 사용되는 메모리 위치에 대한 이름입니다. 변수에 저장된 값은 프로그램 실행 중에 변경될 수 있습니다.
특징
값의 변경 가능: 변수에 저장된 값은 프로그램 실행 중에 변경될 수 있습니다.
메모리 주소: 변수는 메모리 위치를 가리키는 이름으로, 해당 메모리 위치에 값을 저장합니다.
타입: 대부분의 프로그래밍 언어에서는 변수에 특정 데이터 타입(예: 정수, 부동 소수점, 문자열 등)이 있습니다.
예시
python
코드 복사
# Python 예시
x = 10 # 변수 x에 정수 10을 저장
x = x + 5 # 변수 x의 값을 5 증가시킴
print(x) # 출력: 15
# Java 예시
int y = 20; // 변수 y에 정수 20을 저장
y = y * 2; // 변수 y의 값을 2배로 변경
System.out.println(y); // 출력: 40
상수 (Constant)
상수는 프로그램에서 한 번만 값을 할당하고, 그 이후에는 값이 변경되지 않는 메모리 위치에 대한 이름입니다.
특징
값의 불변성: 상수에 저장된 값은 프로그램 실행 중에 변경되지 않습니다.
의미 부여: 코드에서 상수를 사용하면 특정 값에 의미를 부여할 수 있어 코드 가독성을 높이고 유지보수를 쉽게 합니다.
타입: 상수도 변수와 마찬가지로 특정 데이터 타입을 가집니다.
예시
python
코드 복사
# Python 예시
PI = 3.14159 # 상수 PI에 값을 할당
print(PI) # 출력: 3.14159
# Java 예시
final int DAYS_IN_WEEK = 7; // 상수 DAYS_IN_WEEK에 값을 할당
System.out.println(DAYS_IN_WEEK); // 출력: 7
비교
| 특성 | 변수 (Variable) | 상수 (Constant) |
| 값의 변경 | 가능 (mutable) | 불가능 (immutable) |
| 메모리 사용 | 메모리 주소에 값이 저장됨 | 메모리 주소에 값이 저장됨 |
선언 방식 .대부분의 언어에서 var, let, 타입명 등 사용. 대부분의 언어에서 const, final 사용
용도 . 변할 수 있는 데이터를 저장할 때 사용. 변하지 않는 데이터를 저장할 때 사용
변수와 상수의 사용 사례
변수: 사용자 입력 값을 저장하거나, 반복문에서 카운터로 사용하거나, 계산 결과를 저장하는 등 프로그램 실행 중 변할 수 있는 값을 저장하는 데 사용됩니다.
상수: 물리적 상수(예: 원주율 PI), 설정 값(예: 최대 연결 수), 변하지 않는 데이터(예: 요일 수 DAYS_IN_WEEK)를 저장하는 데 사용됩니다.
요약
변수: 값이 변할 수 있는 저장소로, 프로그램 실행 중 값을 변경할 수 있습니다.
상수: 값이 변하지 않는 저장소로, 프로그램 실행 중 값이 변경되지 않습니다.
이 두 개념은 프로그래밍에서 데이터를 효율적으로 관리하고, 코드의 가독성과 유지보수성을 높이는 데 필수적입니다.
변수(variable)는 프로그램 실행 중 값이 변할 수 있는 메모리 공간을 나타내는 것입니다. 즉, 어떤 값을 저장하고 이후에 다시 그 값을 읽어오거나 수정할 수 있습니다. 변수는 이름과 값으로 구성되며, 대부분의 프로그래밍 언어에서는 특정 형식(타입)의 값만 저장할 수 있도록 제한됩니다.
예를 들어, Python 언어에서 정수값을 저장하는 변수를 선언하려면 int 타입을 지정해주어야 합니다.
python
Copy code
x = 10 # 정수값 10을 x라는 변수에 저장
y = "Hello" # 문자열 "Hello"를 y라는 변수에 저장
z = 3.14 # 실수값 3.14를 z라는 변수에 저장
상수(constant)는 한번 할당된 값이 변경되지 않는 고정된 값을 가지는 변수입니다. 상수는 주로 변하지 않는 값이나 미리 정해진 값을 저장하는데 사용됩니다.
예를 들어, 파이썬에서 상수를 정의하려면 const 키워드 대신 final 키워드를 사용합니다.
python
Copy code
FINAL_VALUE = 100 # 상수 FINAL_VALUE에는 100이라는 값이 영원히 유지됨
요약하자면, 변수는 프로그램 실행 중 값이 변하는 메모리 공간을 나타내며, 상수는 한번 할당된 값이 변경되지 않는 고정된 값을 가지는 변수입니다. 두 가지 모두 프로그램 코드 내에서 값을 저장하고 처리하는 데 필수적인 요소입니다.
컴퓨터 프로그래밍에서 기본 자료형(primitive data type)은 컴퓨터 시스템에서 직접 다룰 수 있는 가장 작은 단위의 데이터 유형을 말합니다. 일반적으로 정수, 실수, 문자, 문자열 등이 포함되며, 각 운영체제나 프로그래밍 언어마다 다를 수 있습니다.
반면에 구조화된 자료형(structured data type)은 여러 개의 기본 자료형을 조합하여 만든 복합적인 데이터 유형을 말합니다. 대표적인 예로는 배열, 리스트, 스택, 큐, 데크, 맵, 세트 등이 있으며, 이러한 자료형들은 다양한 문제 해결에 유용하게 사용됩니다.
요약하면, 기본 자료형은 컴퓨터 시스템에서 직접 다룰 수 있는 작은 단위의 데이터 유형이며, 구조화된 자료형은 여러 개의 기본 자료형을 조합하여 만든 복합적인 데이터 유형입니다. 각각의 특징과 용도에 따라 적절하게 선택하여 사용해야 합니다.
파스 트리(parse tree) 또는 파싱 트리(parsing tree)는 올바른 문장에 대해 트리 구조로 나타낸 것을 말하며, 문맥 자유 문법에서 중요하게 다루는 개념입니다. 1
파스 트리는 입력 언어의 문법을 구체적으로 반영하며, 문법을 가르치는 데에도 사용됩니다.
정규 문법(regular grammar)은 정규 언어를 기술하는 형식 문법입니다. 1
4-튜플<N, Σ, P, S>에서 생성 규칙 P가 으로만 구성되어 있거나(우선형 문법),으로만 구성되어 있는 것(좌선형 문법)을 말합니다. 이때,이고 ε는 길이가 0인 문자열입니다.
형식 문법 계층 간의 관계에 대해 말씀드리겠습니다.
형식 문법은 크게 어휘부와 구문부로 나눌 수 있습니다.
어휘부 는 문장에서 사용되는 단어들을 정의하고, 이를 기호로 변환하는 역할을 합니다. 예를 들어, 영어 문장에서 "Hello"라는 단어가 나오면 이를 기호로 변환하여 저장합니다.
구문부 는 어휘부에서 변환된 기호들을 이용하여 문장의 구조를 파악하는 역할을 합니다. 예를 들어, 영어 문장에서 "Hello"라는 단어와 "World"라는 단어가 있으면 이를 연결하여 "Hello World"라는 문장을 만듭니다.
구문부는 다시 구문 분석 도식과 구문 분석표로 나눌 수 있습니다.
구문 분석 도식 은 문장의 구조를 그림으로 나타낸 것입니다. 예를 들어, "Hello World"라는 문장은 주어인 "Hello"와 동사인 "World"로 이루어져 있으며, 이를 그림으로 나타내면 다음과 같습니다.
구문 분석표 는 문장의 구조를 표로 나타낸 것입니다. 예를 들어, "Hello World"라는 문장에서 "Hello"는 명사이고 "World"는 동사라는 정보를 표로 나타내면 다음과 같습니다.
구문 분석 도식과 구문 분석표는 서로 밀접한 관계가 있습니다. 구문 분석 도식에서는 문장의 구조를 그림으로 나타내기 때문에 직관적으로 이해하기 쉽지만, 복잡한 문장의 경우에는 복잡해질 수 있습니다. 반면에 구문 분석표는 문장의 구조를 표로 나타내기 때문에 복잡하고 복잡한 문장도 쉽게 이해할 수 있지만, 직관적으로 이해하기 어려울 수 있습니다.
따라서 형식 문법에서는 어휘부와 구문부를 적절히 조합하여 문장의 구조를 파악하고, 이를 바탕으로 문장을 해석합니다. 이때, 구문 분석 도식과 구문 분석표를 이용하여 문장의 구조를 더욱 정확하게 파악할 수 있습니다.
요약하면, 형식 문법은 어휘부와 구문부로 구성되어 있으며, 구문부는 다시 구문 분석 도식과 구문 분석표로 나눌 수 있습니다. 이러한 계층 간의 관계를 잘 이해하고 활용함으로써 보다 정확하고 효율적인 문장 해석이 가능해집니다.
LL(Left to Right) 과 LR(Left to Right) 은 구문 분석 방법 중 하나로, 각각 다음과 같은 특징을 가지고 있습니다. 1
LL 구문 분석
구문 분석 시 왼쪽부터 시작하여 오른쪽으로 진행합니다. 1 파싱 과정에서 현재 토큰과 이전 토큰만을 이용하여 결정을 내립니다. 결정 트리가 깊어져 구문 분석 속도가 느릴 수 있습니다.
LR 구문 분석
구문 분석 시 왼쪽부터 시작하여 오른쪽으로 진행합니다. 1 파싱 과정에서 현재 토큰과 이후 토큰까지 미리 예측하여 결정을 내립니다. 결정 트리가 짧아져 구문 분석 속도가 빠를 수 있습니다.
두 방법 모두 장단점이 있으므로, 상황에 따라 적절한 방법을 선택하여 사용하는 것이 중요합니다.
구문 분석키(parse key)란 데이터베이스에서 쿼리문의 구문을 분석하여 최적의 실행 계획을 수립하는 데 사용되는 정보입니다.
쿼리문을 분석하여 테이블명, 컬럼명, 연산자 등의 정보를 추출하며, 이를 기반으로 인덱스를 활용하거나 조인 방식을 결정하는 등의 작업을 수행합니다.
종류로는 연산자 우선순위, 조인 순서, 인덱스 유무 등이 있습니다.
구문 분석키는 쿼리 성능에 큰 영향을 미치므로, 개발자는 쿼리문을 작성할 때 구문 분석키를 고려해야 합니다.
문법 표기법 중 BNF(Backus-Naur Form)는 구문 분석을 위한 형식 언어를 정의하는데 사용되는 표준 문법 표기법입니다. 이 문법은 구문 요소들 간의 관계를 나타내는 규칙 집합으로 구성되며, 각 규칙은 하나 이상의 구문 요소 또는 문자열을 나타냅니다. 일반적으로 BNF는 다음과 같은 세 가지 유형의 규칙으로 구성됩니다.
정의 규칙
특정 심볼이나 문자열을 정의하는 규칙입니다. 예를 들어, "S"라는 심볼이 있다면 이를 정의하는 규칙은 다음과 같습니다. S ::= A | B 여기서 S는 A나 B 중 하나로 대체될 수 있음을 의미합니다.
선택 규칙
두 개 이상의 선택지 중 하나를 선택하는 규칙입니다. 예를 들어, "E"라는 심볼이 있고 E가 A나 B 중 하나라면 다음과 같이 나타낼 수 있습니다. E ::= A | B
확장 규칙
기존 심볼을 다른 심볼로 대체하는 규칙입니다. 예를 들어, "T"라는 심볼이 있고 T가 S와 E로 이루어진다면 다음과 같이 나타낼 수 있습니다. T ::= S E
BNF는 구문 분석을 위한 형식 언어를 정의하는데 매우 유용한 문법 표기법이지만, 때로는 이해하기 어려울 수도 있습니다. 따라서 BNF를 사용할 때는 적절한 설명과 함께 사용하는 것이 좋습니다. 또한, 다양한 문법 표기법이 존재하므로 상황에 따라 적절한 문법 표기법을 선택하는 것이 중요합니다.
프로그래밍 언어의 구문(Syntax) 표기법에는 여러 가지 방식이 있습니다. 가장 널리 사용되는 표기법으로는 **BNF(Backus-Naur Form)**과 **EBNF(Extended Backus-Naur Form)**이 있습니다. 또한 문법 다이어그램과 같은 시각적 표기법도 사용됩니다.
1. BNF (Backus-Naur Form)
BNF는 프로그래밍 언어의 구문을 형식적으로 표현하기 위해 개발된 표기법입니다. BNF는 두 가지 주요 구성 요소를 가지고 있습니다:
비종결 기호(Non-terminal symbol): 더 작은 구문 단위로 분해될 수 있는 요소.
종결 기호(Terminal symbol): 더 이상 분해되지 않는 기본 요소.
BNF 규칙의 기본 형식
go
코드 복사
<symbol> ::= expression
예시
BNF를 사용하여 간단한 산술 표현식을 정의할 수 있습니다:
go
코드 복사
<expression> ::= <term> | <expression> "+" <term>
<term> ::= <factor> | <term> "*" <factor>
<factor> ::= <number> | "(" <expression> ")"
<number> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
2. EBNF (Extended Backus-Naur Form)
EBNF는 BNF를 확장한 형태로, 더 풍부하고 읽기 쉬운 표기법을 제공합니다. EBNF는 선택 사항, 반복, 그룹화를 위한 추가 표기법을 포함합니다.
EBNF 규칙의 기본 형식
makefile
코드 복사
symbol = expression;
EBNF 추가 표기법
선택 사항(Option): [ ... ]
반복(Repetition): { ... }
그룹화(Grouping): ( ... )
예시
EBNF를 사용하여 동일한 산술 표현식을 정의할 수 있습니다:
makefile
코드 복사
expression = term | expression "+" term;
term = factor | term "*" factor;
factor = number | "(" expression ")";
number = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9";
3. 문법 다이어그램 (Syntax Diagram)
문법 다이어그램은 구문 규칙을 시각적으로 표현하는 방법입니다. 이는 특히 복잡한 구문을 이해하기 쉽게 만듭니다.
예시
산술 표현식을 나타내는 문법 다이어그램을 예로 들면:
expression:
lua
코드 복사
+---+ +---+
| |-->| + |-->| |
+---+ +---+ +---+
term:
lua
코드 복사
+---+ +---+
| |-->| * |-->| |
+---+ +---+ +---+
실제 프로그래밍 언어 예시
Python 구문 예시 (EBNF)
Python 함수 정의를 EBNF로 표현하면 다음과 같습니다:
makefile
코드 복사
function_definition = "def" function_name "(" parameters ")" ":" suite ;
function_name = identifier ;
parameters = [ parameter { "," parameter } ] ;
parameter = identifier [ "=" expression ] ;
suite = statement | "{" statement { statement } "}" ;
요약
BNF: 기본적인 구문 표기법으로 간단한 규칙을 표현.
EBNF: BNF를 확장한 형태로, 선택 사항, 반복, 그룹화를 표현할 수 있어 더 읽기 쉽고 명확함.
문법 다이어그램: 시각적으로 구문 규칙을 표현하여 이해하기 쉽게 함.
이러한 표기법은 프로그래밍 언어의 구문을 정확하게 정의하고 이해하는 데 필수적입니다.
언어란 사람들 간 의사소통을 위한 수단으로서 구문(syntax), 의미(semantics), 순서(order) 세 가지 요소로 구성됩니다.
구문
언어의 문법적인 규칙을 말합니다. 예를 들어, 영어에서는 주어+동사+목적어 순으로 문장이 구성되며, 단어들은 일정한 규칙에 따라 조합되어야 올바른 문장이 됩니다.
의미
언어의 뜻을 나타내는 것으로, 단어와 문장의 의미를 이해하고 해석하는 것을 말합니다.
순서
언어의 어순을 말하며, 어떤 언어든지 특정한 어순이 존재합니다.
이러한 언어의 세 가지 요소는 서로 밀접하게 연관되어 있으며, 언어를 이해하고 표현하는 데 있어서 매우 중요한 역할을 합니다. 또한 각 나라마다 문화나 역사, 사회적 배경 등에 따라 다양한 언어가 존재하며 이러한 언어들은 각각의 특성을 가지고 있습니다. 따라서 언어를 공부하고자 하는 경우에는 해당 언어의 구문, 의미, 순서를 함께 학습해야 하며 이를 통해 보다 효과적으로 언어를 이해하고 구사할 수 있게 됩니다.
구문(Syntax): 프로그래밍 언어에서 코드를 작성하는데 필요한 문법 규칙을 말합니다. 예를 들어, 변수 선언 방법, 함수 호출 방법, 조건문 및 반복문의 사용 방법 등이 포함됩니다.
의미(Semantics): 프로그램 실행 중 일어나는 동작이나 결과를 정의하는 것으로, 구문과는 달리 언어 자체보다는 컴파일러나 인터프리터가 이해해야 하는 내용을 담고 있습니다.
순서는(Sequence): 하나 이상의 구문 또는 문장들의 집합으로서 특정 작업을 수행하기 위한 일련의 단계들을 나타냅니다. 이러한 단계들은 일반적으로 순차적으로 처리되며, 각 단계에서는 입력 데이터를 조작하거나 계산을 수행하고 출력 값을 반환합니다.
프로그래밍 언어의 구문, 의미, 순서에 대해 설명하겠습니다.
1. 구문 (Syntax)
구문은 프로그래밍 언어에서 프로그램이 어떻게 작성되어야 하는지를 규정하는 규칙의 집합입니다. 이는 컴파일러나 인터프리터가 코드를 분석하고 이해하기 위해 필요한 구조적 규칙을 정의합니다.
- 구문의 역할: 프로그램 코드의 구조를 정의하고, 코드가 문법적으로 올바른지를 검증합니다.
- 구문 오류: 구문 규칙에 맞지 않게 코드를 작성하면 구문 오류(Syntax Error)가 발생합니다. 예를 들어, 세미콜론(;)을 빠뜨리거나 중괄호({})를 제대로 닫지 않으면 구문 오류가 발생합니다.
- 예시:
python코드 복사# Python 구문 예시 if x > 10: print("x is greater than 10") else: print("x is 10 or less")
2. 의미 (Semantics)
의미는 프로그램 코드가 수행하는 동작이나 행동을 설명합니다. 이는 구문이 어떻게 해석되고 실행되는지를 정의합니다.
- 정적 의미(Static Semantics): 컴파일 시점에서 확인할 수 있는 의미로, 변수 타입의 일치, 스코프 규칙 등을 포함합니다.
- 동적 의미(Dynamic Semantics): 프로그램 실행 시점에서 발생하는 동작을 정의합니다. 이는 프로그램의 논리와 흐름을 포함합니다.
- 예시:
python코드 복사# Python 의미 예시 x = 5 # 변수 x에 5를 할당 (정적 의미: x는 정수형 변수) y = x + 10 # x의 값에 10을 더하여 y에 할당 (동적 의미: x의 현재 값이 5이므로 y는 15가 됨)
3. 순서 (Order of Execution)
순서는 프로그램 코드가 실행되는 순서를 의미합니다. 프로그래밍 언어마다 코드 실행 순서가 다를 수 있으며, 이는 프로그램의 동작 방식에 큰 영향을 미칩니다.
- 제어 흐름: 프로그램의 실행 순서를 제어하는 구조를 포함합니다. 조건문(if, else), 반복문(for, while), 함수 호출 등이 제어 흐름의 예입니다.
- 선언 및 초기화 순서: 변수나 함수가 선언되고 초기화되는 순서도 중요한 역할을 합니다.
- 예시:
python코드 복사# Python 순서 예시 def calculate_sum(a, b): return a + b # 함수가 호출될 때 이 부분이 실행됨 x = 5 y = 10 result = calculate_sum(x, y) # 함수가 호출되고 계산이 실행됨 print(result) # 15 출력
통합 예시
아래 예시를 통해 구문, 의미, 순서가 어떻게 통합되는지 살펴보겠습니다:
- 구문: def, return, 변수 선언 name = "Alice", 함수 호출 greet(name), 출력문 print(message) 등의 구문 요소들이 프로그램의 구조를 정의합니다.
- 의미: 각 구문이 수행하는 동작, 예를 들어 함수 greet는 이름을 받아 환영 메시지를 반환하고, print 함수는 메시지를 출력합니다.
- 순서: 프로그램이 정의된 순서대로 실행됩니다. 먼저 함수가 정의되고, 변수 name이 초기화되며, 함수가 호출되고, 결과가 출력됩니다.
이와 같이 프로그래밍 언어의 구문, 의미, 순서가 결합되어 프로그램이 작성되고 실행됩니다.
인터프리터(interpreter)는 프로그래밍 언어의 소스 코드를 바로 실행하는 컴퓨터 프로그램을 말하며, 인터프리터 언어는 소스 코드를 한 번에 기계어로 변환하는 컴파일러와 달리 컴파일 하지 않고 소스 코드를 한 줄씩 읽어 들여 실행합니다. 12
컴파일 하는 과정이 없기 때문에 컴파일 하는 시간은 소요되지 않으나, 인터프리터 언어는 실행파일을 별도로 생성하지 않기 때문에 실행 시마다 인터프리트 과정이 반복 수행되어 실행 속도가 느리다는 단점이 있습니다. 12
인터프리터 언어의 종류로는 Python, Javascript, Ruby 등이 있습니다.
디버깅은 프로그램 개발 과정에서 발생하는 오류를 찾고 수정하는 과정입니다. 12
효과적인 디버깅을 위해서는 다음과 같은 단계를 따를 수 있습니다. 13
문제의 원인 파악
로그 파일, 스택 트레이스 등 다양한 도구와 기법을 사용하여 문제의 원인을 파악합니다. 1
해결책 찾기
디버깅 도구를 사용하여 코드를 한 줄씩 실행 하면서 변수의 값을 확인하고 문제가 있는 부분을 찾습니다. 24
수정
버그의 원인을 찾은 후, 이를 수정하고 테스트합니다. 수정된 코드가 다른 오류를 발생시키지 않는지 다시 테스트하고, 문제가 해결되었는지 확인합니다. 13
디버깅은 개발자에게 중요한 기술이며, 로그 메시지를 사용하여 코드 실행 중간에 값을 확인하고 문제가 발생하는 부분을 식별할 수 있습니다. 또, 스택 추적을 사용하여 어떤 함수가 호출 되었는지와 그 함수 내부에서 어떤 일이 발생했는지 추적할 수 있습니다.
자바 프로그램은 다음과 같은 단계를 거쳐 실행됩니다.
소스 코드 작성
자바 언어로 작성된 소스 코드를 작성합니다.
컴파일
작성한 소스 코드를 컴파일러를 이용하여 바이트 코드로 변환합니다.
바이트 코드 실행
변환된 바이트 코드를 자바 가상 머신(JVM)에서 실행합니다.
자바 가상 머신은 운영체제와는 독립적으로 동작하므로, 자바 프로그램은 어떤 운영체제에서도 실행할 수 있습니다. 또한, 자바 가상 머신은 다양한 하드웨어 환경을 추상화하여 자바 프로그램이 일관된 방식으로 동작할 수 있도록 해줍니다.
즉 자바 프로그램은 소스 코드를 작성하고 컴파일러를 이용하여 바이트 코드로 변환한 뒤 자바 가상 머신에서 실행됩니다. 이때 자바 가상 머신은 운영체제와 하드웨어 환경을 추상화하여 자바 프로그램이 일관된 방식으로 동작할 수 있도록 해줍니다.
컴퓨터 프로그램이 실행되는 일반적인 절차는 다음과 같습니다.
번역
코드를 운영체제가 이해할 수 있는 기계어로 바꾸는 작업입니다. 이 과정에서는 컴파일러 또는 인터프리터가 사용됩니다.
적재
번역된 기계어 코드는 메모리에 적재됩니다. 이 때, 필요한 라이브러리 및 데이터 파일도 함께 적재됩니다.
실행
적재된 코드가 CPU에서 실행됩니다. 이 과정에서 입력 값을 받아 처리하고 결과를 출력합니다.
위의 세 가지 단계는 서로 밀접하게 연관되어 있으며, 하나의 프로그램이 실행되기 위해서는 위의 모든 단계가 성공적으로 이루어져야 합니다. 이러한 과정은 대개 자동으로 이루어지며, 개발자는 각각의 단계를 직접 관리하지 않아도 됩니다. 다만, 특별한 상황에서는 각 단계를 수동으로 조정해야 할 수도 있습니다. 예를 들어, 코드를 수정한 후에는 다시 번역하고 적재해야 하며, 실행 중 발생한 오류를 해결하기 위해 적재된 코드를 수정해야 할 수도 있습니다.
일반적으로 컴퓨터 프로그램은 다음과 같은 단계를 거쳐 동작합니다.
소스코드 작성
먼저 개발자가 원하는 언어로 프로그램의 로직을 담은 소스코드를 작성합니다.
컴파일
작성한 소스코드는 컴파일러라는 도구를 통해 기계어로 변환됩니다. 이를 통해 CPU나 GPU 등 하드웨어 장치에서 직접 실행될 수 있는 바이너리 파일이 만들어집니다.
링크
컴파일 과정에서 만들어진 오브젝트 파일들은 링크 과정을 거쳐 하나로 합쳐져 실행 파일이 됩니다. 이때 라이브러리 함수들도 함께 호출되어 필요한 자원들을 가져옵니다.
실행
마지막으로 완성된 실행 파일을 컴퓨터에서 실행하면 해당 프로그램이 작동하게 됩니다.
이러한 과정은 대부분 자동화되어 있어 개발자는 각 단계를 따로 신경쓰지 않아도 되는 경우가 많습니다. 그러나 때로는 특정 문제 해결을 위해 일부 단계를 수동으로 조작해야 하는 경우도 있을 수 있습니다.
컴파일러는 소스 코드를 작성한 프로그래머가 작성한 프로그램을 기계어로 변환해주는 프로그램입니다. 컴파일러는 소스 코드를 번역하고, 오류를 찾아내고, 실행 가능한 프로그램으로 변환하는 역할을 수행합니다. 12
컴파일러에는 여러 종류가 있으며, 이는 언어에 따라 다양한 특징과 기능을 제공합니다. 1
대표적인 컴파일러 종류는 다음과 같습니다. 13
C 컴파일러
C 언어로 작성된 소스 코드를 번역하는 컴파일러입니다. 가장 많이 사용되는 언어 중 하나이며, C 언어에 대한 표준을 준수하여 작성된 프로그램을 처리할 수 있습니다. 12
C++ 컴파일러
C++ 언어로 작성된 소스 코드를 번역하는 컴파일러입니다. C 언어와 호환되며, 객체 지향 프로그래밍을 지원하는 다양한 기능을 제공합니다. 13
Java 컴파일러
Java 언어로 작성된 소스 코드를 번역하는 컴파일러입니다. Java는 플랫폼 독립적인 언어로, 소스 코드는 바이트 코드로 변환되고, JVM(Java Virtual Machine)에서 실행됩니다.
프로그래밍 언어는 컴퓨터 시스템에서 실행되는 코드를 작성하기 위한 언어입니다.
컴퓨터 과학에서는 다양한 종류의 프로그래밍 언어가 있으며, 각 언어는 특정한 목적이나 환경에서 사용됩니다. 예를 들어, 웹 개발에는 HTML, CSS, JavaScript 등의 언어가 사용되고, 모바일 앱 개발에는 Java, Swift 등의 언어가 사용됩니다. 또한, 데이터베이스 관리에는 SQL, Python 등의 언어가 사용됩니다.
각 언어는 문법, 구문, 어휘, 연산자, 자료형 등의 요소로 구성되어 있으며, 이를 통해 프로그램을 작성하고 실행할 수 있습니다. 이러한 언어들은 일반적으로 컴파일러나 인터프리터 등의 번역기를 사용하여 기계어로 변환됩니다.
프로그래밍 언어는 개발자들 간의 의사소통 수단으로도 사용되며, 소프트웨어 개발 과정에서 매우 중요한 역할을 담당합니다. 따라서 많은 사람들이 자신이 선호하는 언어를 선택하여 프로그래밍을 하고 있습니다.
LISP과 프롤로그는 모두 인공지능 분야에서 많이 사용되는 프로그래밍 언어입니다. 하지만 두 언어는 서로 다른 특징을 가지고 있습니다.
개발 목적
LISP은 인공지능 분야에서 문제 해결을 위한 도구로 개발되었습니다. 반면에 프롤로그는 데이터 분석 및 시각화를 위해 개발되었습니다.
문법
LISP은 수식 형태의 문법을 사용하며, 함수형 프로그래밍에 특화되어 있습니다.반면에 프롤로그는 객체지향 프로그래밍에 특화되어 있습니다.
사용 용도
LISP은 인공지능 분야에서 많이 사용되며, 특히 머신러닝과 딥러닝 분야에서 많이 사용됩니다.프롤로그는 데이터 분석 및 시각화 분야에서 많이 사용됩니다.
두 언어는 각각의 특성에 따라 사용 용도가 다르며, 필요한 상황에 따라 선택적으로 사용해야 합니다.
인공지능 언어는 인간의 언어를 기계가 이해하고 처리할 수 있도록 만든 언어입니다. 인공지능 언어는 자연어 처리, 음성 인식, 기계 번역 등 다양한 분야에서 사용되며, 다음과 같은 특징을 가지고 있습니다.
자동화
자동으로 문장을 분석하고 의미를 파악하여 적절한 응답을 제공합니다.
정확성
정확한 문장 분석과 의미 파악을 통해 정확한 응답을 제공합니다.
학습 가능성
학습을 통해 더욱 발전할 수 있으며, 다양한 상황에서도 유연하게 대처할 수 있습니다.
다양한 분야 적용 가능성
자연어 처리, 음성 인식, 기계 번역 등 다양한 분야에서 사용될 수 있습니다.
대표적인 인공지능 언어로는 알파고, 구글 딥마인드, 네이버 하이퍼클로바등이 있습니다.
바인딩 시간(binding time)은 프로그램 실행 시 변수와 상수가 실제 값에 바인딩되는 시점을 말합니다. 즉, 변수나 상수가 선언되고 초기값이 할당되거나 연산식이 계산되어 값이 결정되는 시점을 말합니다.
예를 들어, 지역변수는 함수 내에서 선언되고 해당 함수가 호출될 때 값이 바인딩되며, 전역변수는 프로그램 시작 시 값이 바인딩됩니다.
바인딩 시간은 다음과 같이 세 가지 단계로 나눌 수 있습니다.
바인딩 전
변수나 상수가 선언되었지만 아직 값이 할당되지 않은 상태입니다. 이 단계에서는 변수나 상수의 타입과 크기만 결정됩니다.
바인딩 중
변수나 상수에 값이 할당되거나 연산식이 계산되어 값이 결정되는 상태입니다. 이 단계에서는 변수나 상수의 값이 확정됩니다.
바인딩 후
변수나 상수의 값이 완전히 결정된 상태입니다. 이후에는 변수나 상수의 값이 변경될 수 없습니다.
프로그램의 성능을 분석할 때 중요한 지표 중 하나이며, 바인딩 시간이 빠를수록 프로그램의 실행 속도가 빨라집니다.
어셈블리 언어
장점
하드웨어 제어가 용이하며, 메모리 관리가 효율적이고, 속도가 빠릅니다.
단점
문법이 어렵고, 호환성이 낮으며, 이식성이 떨어집니다.
인터프리터
장점
원시 코드를 바로 실행할 수 있어 디버깅이 쉽고 개발 시간을 단축할 수 있습니다.
단점
컴파일 방식보다 느리고, 메모리 사용량이 많습니다.
인터프리터(interpreter)는 고급 언어로 작성된 원시 코드를 한 줄씩 읽어 들여서 즉시 해석하고 실행하는 프로그램입니다. 컴파일러와는 달리 목적 코드를 생성하지 않으며, 원시 코드를 직접 실행합니다. 이러한 방식은 컴파일 방식보다 느리지만, 원시 코드를 바로 실행할 수 있기 때문에 디버깅이 쉽고 개발 시간을 단축할 수 있다는 장점이 있습니다.
종류로는 RPG 인터프리터, SQL 인터프리터, 자바스크립트 인터프리터 등이 있습니다.
어셈블리언어(assembly language)란 기계어의 명령부와 번지 부를 사람이 이해하기 쉬운 기호와 1:1로 대응시켜 기호화한 프로그램 언어를 의미합니다. 1
어셈블리 언어로 작성된 프로그램은 어셈블러에 의해 기계어로 번역되어야만 실행이 가능하며, 표 지부, 연산부, 피연산부로 구성됩니다. 1
표지 부
프로그램에서 명령들을 참조하기 위해 명령 집단에 붙여지는 이름입니다. 1
연산부
move(이동), add(덧셈), subtract(뺄셈) 등 수행을 위한 특별한 명령들의 기호로 되어 있습니다. 1
피연산부
데이터가 처리되어 저장될 레지스터나 저장 장소를 나타냅니다.
전자계산기에 대한 전문지식이 있어야 사용할 수 있으며, 기종마다 다르기 때문에 호환성이 없다는 특징이 있습니다
사용자가 요청한 프로그램 수행순서는 다음과 같습니다.
사용자 요구사항 분석
사용자가 원하는 작업 또는 목표를 명확하게 이해하고 필요한 정보나 자원을 수집합니다.
계획 수립
사용자 요구사항을 충족시키기 위한 계획을 세우고 일정, 예산, 인력 등을 결정합니다.
설계
사용자 요구사항을 반영하여 시스템이나 소프트웨어를 설계하고 구현 방법을 결정합니다.
구현
설계한 내용을 바탕으로 실제 시스템이나 소프트웨어를 개발하고 테스트합니다.
시험 및 평가
구현된 시스템이나 소프트웨어를 시험하고 성능, 안정성, 보안 등을 평가합니다.
배포
완성된 시스템이나 소프트웨어를 배포하고 유지보수를 진행합니다.
유지보수
사용자 요구사항 변경이나 오류 수정 등을 위해 지속적으로 시스템이나 소프트웨어를 개선하고 보완합니다.
종료
프로젝트가 완료되면 결과를 보고하고 관련 문서를 보관합니다.
위 과정은 일반적인 프로그래밍 프로세스이지만 각 프로젝트마다 상황에 따라 다를 수 있으므로 적절한 절차를 선택하고 조정해야 합니다. 또한 이 과정에서는 다양한 도구와 기술이 사용되며 팀 단위로 협업이 이루어집니다. 따라서 효과적인 커뮤니케이션과 역할 분담이 필수적입니다.
'경제' 카테고리의 다른 글
| 5200만명 회원, 코스트코 7년만에 연회비 인상 (2) | 2024.07.11 |
|---|---|
| 메가트루파워(비타민)- 유한양행 (4) | 2024.07.10 |
| 아들 자취방 구하기(연희동) (64) | 2024.07.04 |
| 삼성전자, 엔비디아 승인 설 보도 부인 (44) | 2024.07.04 |
| 한미약품 송영숙·임주현 모녀, '경영권 회복' 촉각개인 최대주주 신동국 회장과 지분 6.5% 매매계약…의결권공동행사 약정 (54) | 2024.07.04 |